
ipfs and Merkle DAGs in web3
introduction to IPFS(Interplanetary File System)
ipfs is intended to complement http.
Today’s networks are inefficient and expensive, and network resources are centrally deployed, limiting individual opportunities. In addition, Web pages have an average lifespan of 100 days, making it difficult to store data for long periods of time. IPFS makes it easy to set up an elastic network for mirrored data. The most important point is that ipfs is based on content addressing, similar to the information-centric network we have been studying before, whose naming scheme is also based on content.
IPFS supports the creation of diverse resilient networks without or with persistent availability of Internet backbone connections.
When a file is added to IPFS, it is split into smaller chunks, encrypted hashed, and given a unique fingerprint called a content identifier (CID). (We’ll add to CID later). These CID acts as a permanent record of the files you uploaded at that point in time.
When other nodes look for your uploaded file, they ask their peers who stores the CID reference to your file, and when they download the uploaded file, they cache a copy, thus becoming the provider of your content until the cache is cleared.
Storing characteristic
A node can pin content in order to keep it forever, actually it will discard the content which hasn’t been used in a while. Namely, the node will store what it is interested in and add some information indexing to help figure out which node is storing what.
Uniqueness
If you upload the file with new version to IPFS, then the hash value of the file will be different and so it gets a new CID. Namely, the file stored in the IPFS can prevent censorship and tampering. We also see that the CID is similar to hash value. What’s more, IPFS divides the file into small chunks, so they will be used to reduce the duplications in order to minize the storage.
naming scheme
There is IPNS decentralized naming system, which can be used to find the latest version of the file. And DNSLink can be used to map CIDs to readable DNS names.
IPFS can help
IPFS can help archivist to save different versions of all files, which help preserve the information for generations.
IFPS can help big data fast distributed to users, which can also reduce bandwidth used, thanks to peer-to-peer machanism
IPFS can help researchers fast process datasets stored on IPFS, it is also not centralized.
IPFS can help store large files off-chain and put immutable, permanent links in transactions, that is say, we can save the information not all on-chain.
IPFS can help access data resillient and become indepentent to latency.
content addressing on the decentralized web
Previously, we visit the network resource depending on url, namely the network address of the resource, so sometimes it is difficult for us to remember too many different locations of these in the network.
So what is content addressing? There are two expresstions of the same book you want to find.
“Go into the library, go upstairs and the walk down until the end of corridor, there is a red book with some Latin latters”.
“The name of book is ‘Artificial intelligence’, whose ISBN is …..”
I think these two examples are the best descriptions for location addressing and content addressing respectively. Sometimes the location we remember will not continue to support the resource, that will be terrible. Next we will detailedly demonstrate the two methods.
Location addressing
The most important element is URL in location addressing, which is based on the location where data is stored.
There are a lot of unconveniences, if we visit a website like http://www.baidu.com/cat.jpg, we can’t ensure what we visit is what we really want, although the name seems correct. So the url may cause some malicious operations and we have to trust the centralized authorities.
What’s more , there will be duplications if we visit a website repeatedly in order to download a file. I think there are lots of same files in everyone’s phone.
Content addressing
So what technology we will be using in content addressing, that is hashing value. The hashing function is a onn-direction trapdoor function, which means we can easily map the content to an unique hash value, but it will be nearly impossible to solve the content from the hash value if we don’t have the key.
The hash value is like this:
1 | skdjkdfhidhidfhaajaoihaifhi |
It brings the security, if there are two people want to share their same picture on IPFS, they just calculate the hash value and then ensure the equality. If someone tampers the file, then the hash value of the file will be changed!
So in the decentralized web, if we want to harvest the information from other nodes we don’t know, it doesn’t matter, a hash value of the information will be calculated which will prevent the malicious behaviors.
And if we determine to find a file named “pig.jpg” in a url website, we may lose the content when the host owned by Alice is down. However, in the decentralized web, we can also get the “pig.jpg” from Bob if Bob has this file, and the hash value is the same.
Content Identifiers(CID)
CID is a content addressing form in particular, which is designed for IPFS.
It contains codec and multihash
1 | [codec, multihash] |
codec is used to interpret the data.
multihash contains the type of hash function used and hash value.
The CID is extensively utilized for linking between all kinds of information, and a new data structure came into being—Merkle DAG.
Dedicated data structure—Merkle DAG
Advantages of structured data
If we have so many files like pictures “pig.jpg”, “bird.jpg” and so on, data structure can help us construct a classification about the kind of animal.
What’s more, we can also naming the file by the time combining the name of the animal, like 2023-5-12-pig.jpg.
But if there are a large number of pictures with previous naming method, it is impossible for us to retrieve the picture with the earliest timpstamp because the method of classification is kind and don’t follow the time order, so we should iterating the whole directory.
CID will help us retrieve fast and safely, and the new structure will become chunks and we can search each chunk of them not from the root directory!
Directed Acyclic Graphs (DAGs)
A graph is a mathematical abstraction that is used to represent relationships among a collection of objects.
The following graph is a directed graph
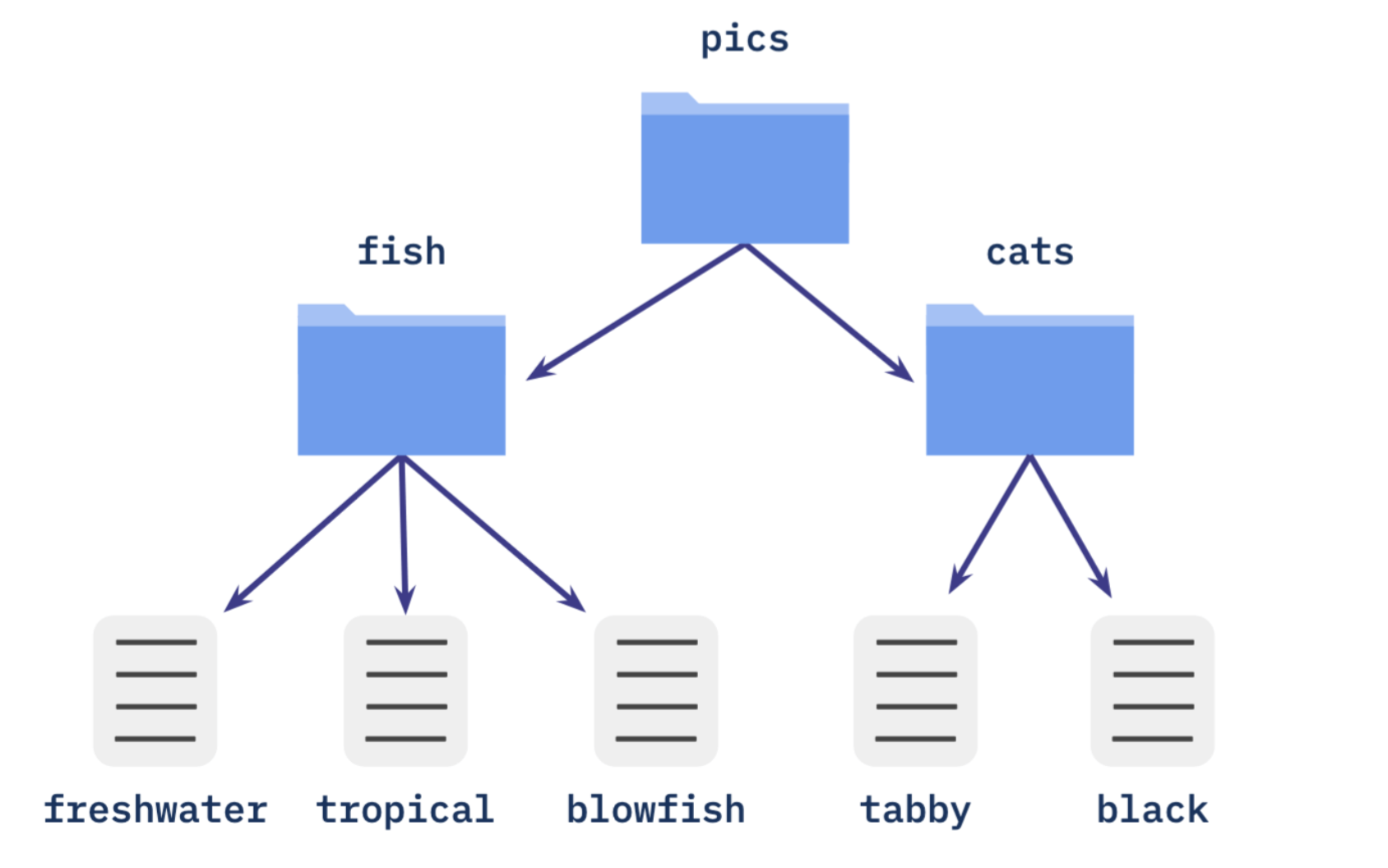
A graph is called a directed graph if each edge has some sense of direction, like the graph above, from root directory “pics” to bottom objects.
A graph is called acyclic if there are no loops in the graph.
So the structure in the IPFS is DAG just like a family tree, we will introduce the details.
Merkle DAGs
We use CIDs to identify each node in the structure, so the the dedicated GADs are call Merkle DAGs. The leaf nodes is the bottom objects, firstly we encode the leaf nodes with CIDs.
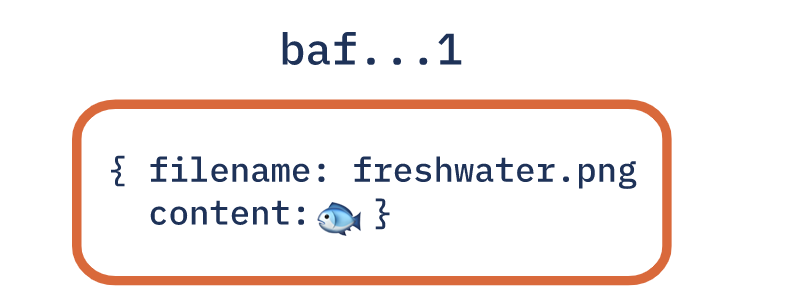
We can see the node containing a filename and the file content, with a label above, the label is a expression of the unique CID. The label is not a part of the node, it is just the address we can locate through.
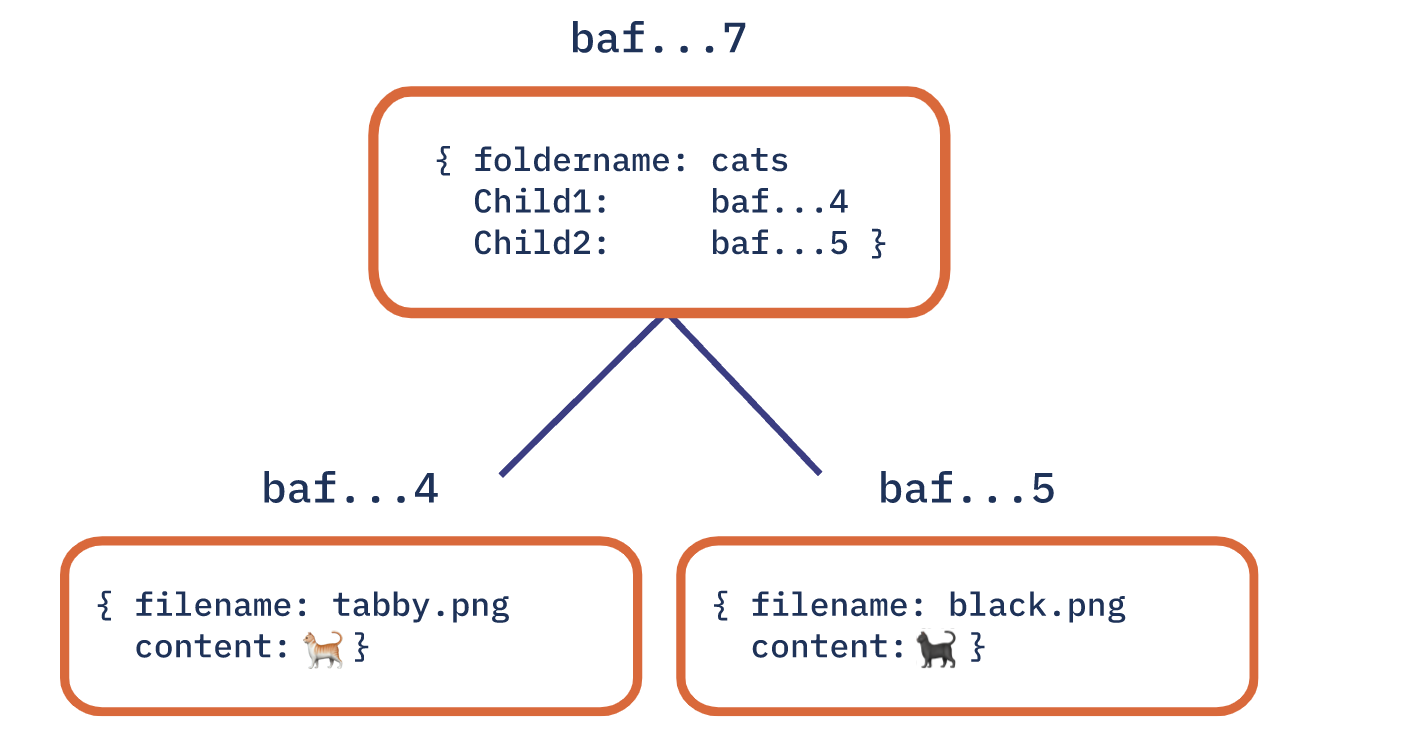
Now we can see, having constructed our leaf nodes, it’s time to create intermidiate node, which is the subdirectory. The intermidiate node includes file names of leaf nodes, a current folder name “cats” and a label CID derived from children data.
This is a small DAG, and the CID of the intermidiate node is to link their children nodes’ CIDs, just from “baf..7” to “baf..4” and “baf..5”.
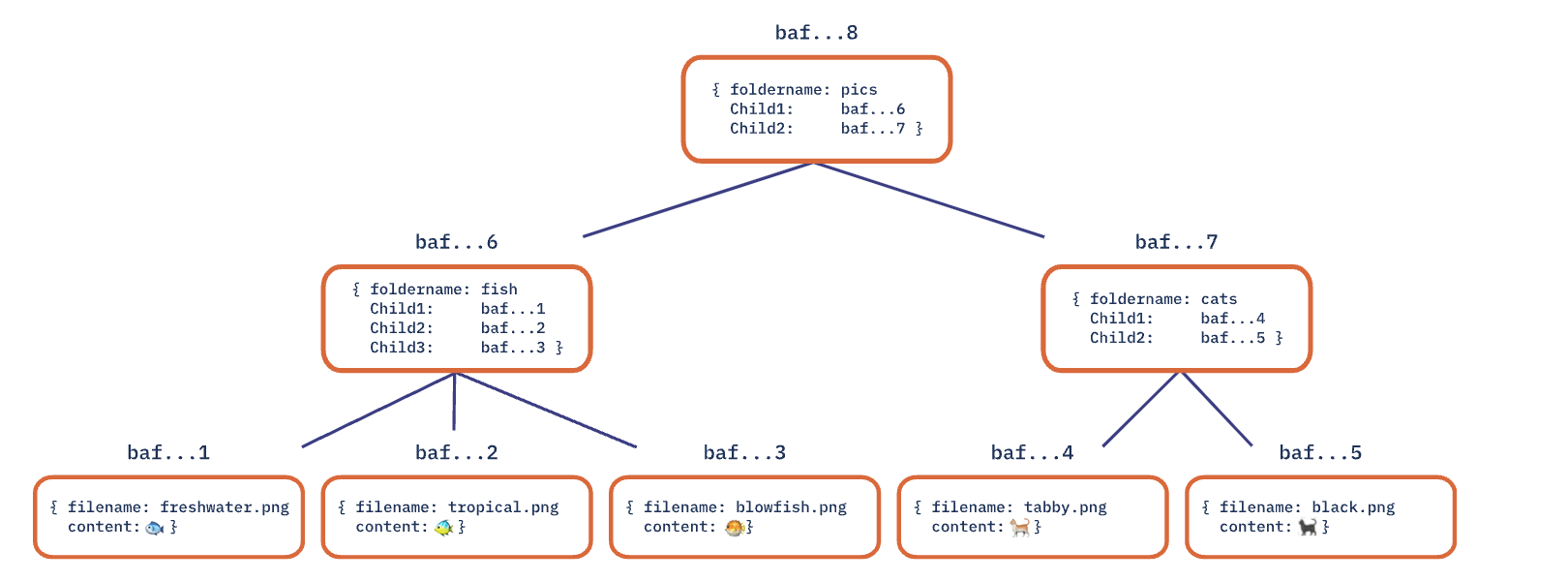
Now we can constuct the whole graph, each node’s CID is derived from all of their descendents, if any of their descendents has changed, their own label will be different, due to hash function.
So let’s conclude, parent nodes can’t be generated until their children nodes’ CIDs have already been done.
And the DAG is acyclic, so when we traverse the whole directory, we will not be trapped in a infinite loop.
Root properties
The most important properties are root preperties, any of nodes’ CID depends on its children’s CIDs, so the root node’s CID identifies the whole DAGs.
There is a useful case, you may create a backup directory previously, and now you find it, you don’t know if the backup directory and the origin directory are the same, so you just compute their CIDs compare them! So you can use this method to get rid of much redundancy!
What I think it most important is that if you want to retrieve the specific file, it is no need to iterate the whole DAG, you can just search the smaller DAG satisfying the file.
Any Node Can Be a Root Node
The subgraph we search can be a new root graph when we want to share this subgraph independently, with its own CID. Meanwhile, the CID of the subgraph will not change because it only depends on its descendents.
What’s more, we can create an interconnected weave of DAGs, let’s look at the picture below.
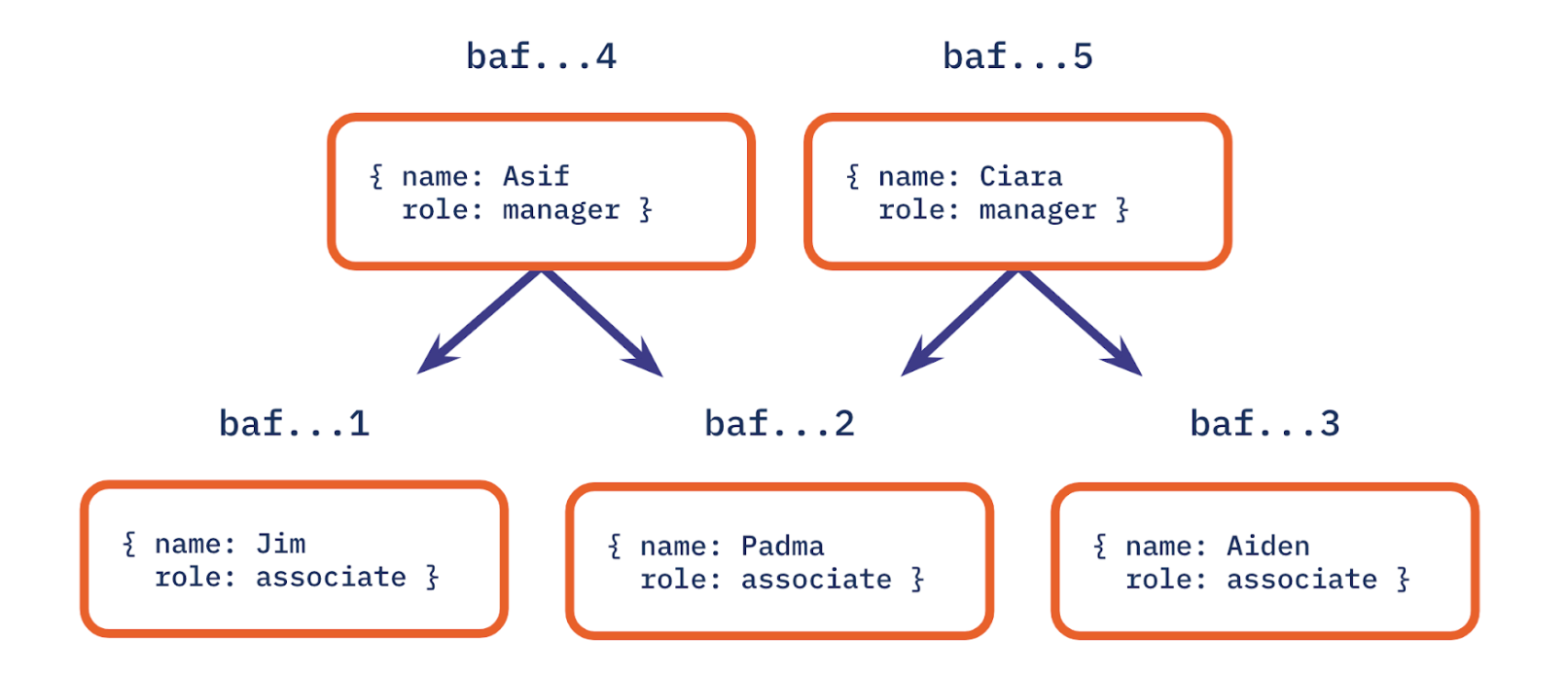
It is apparent that there is no single root node, so we can’t use one single root node to express the whole DAG. However we can add one node at the top as the root node, and it will include the names of two subgraph “baf..4” and “baf…5” , with a CID at the top like “baf …” calculated from children’s node as well.
Distributability
Researchers can manage the large datasets independently, you can copy the datasets so the CIDs are the same, if you want to share them, then you can become a anonymous provider.
The datasets in the centralized storage, will not be accessed when the host is down. However if the datasets are put on IPFS, you can always access them and don’t need to care about where they are from.
- The users don’t need to consider they access the datasets from an unknown node, because everyone can be a provider, you can access the datasets means the CID is correct so the operations are safe.
Deduplication
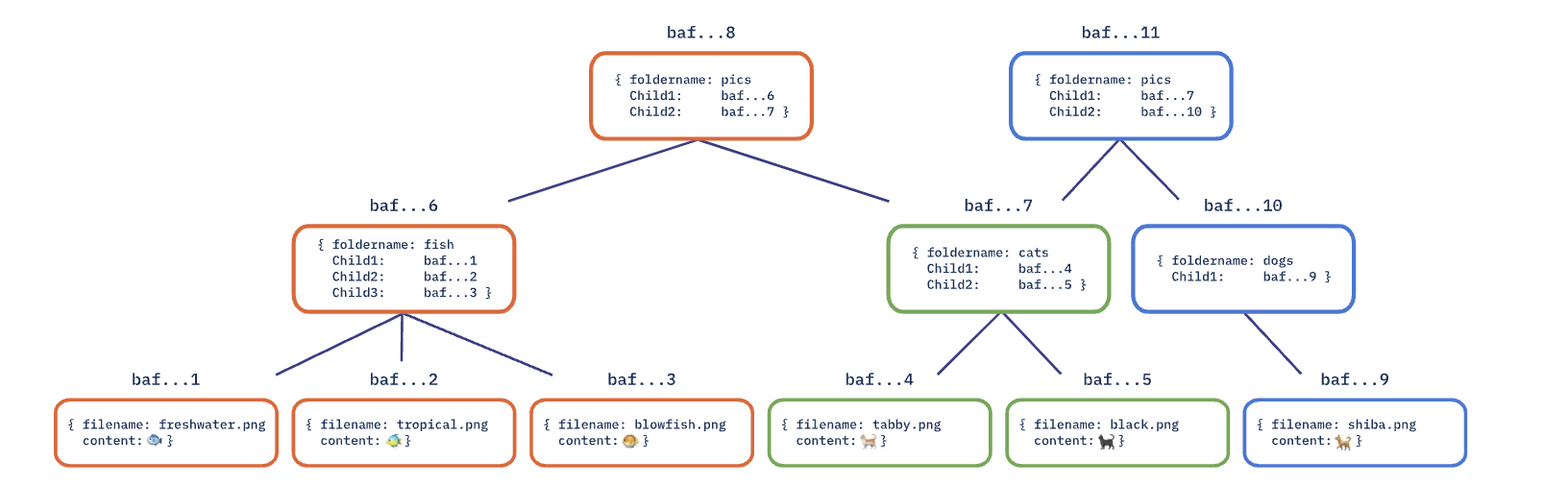
We can see this picture. The DAG can tracking changed files and change the CID. In this case we want to delete the “fish” directory and add a “dogs” directory, but the directory “cats” is the same in both DAG “baf..8” and “baf…11”, so we reuse them to reduce space!
So in the large case, when we are visiting a website, sometimes we see websites with same themes, but our browser will redownload them, which cause deduplications! If we import DAGs, I think it will be helpful for large information retrieval!
 wechat
wechat
