定义线性表 注意
1 2 3 对数组进行封装,在存储空间起始位置即为数组data, 设置最大存储容量,一般不会变 当前长度length,会变化
代码如下
1 2 3 4 5 typedef struct { int data[MAXSIZE]; int length; }SqList;
变化的集合我们用*L,不变的集合我们参数才用L。下面是A = A并B的操作,所以我们知道A是要改变的,传入地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void unionL (List *La, list Lb) { int La_len, Lb_len, i; ElemType e; La_len = ListLength(*La); Lb_len = ListLength(Lb); for (i = 1 ; i <= Lb_len; i++) { GetElem(Lb, i, &e); if (!LocateElem(*La, e)) { ListInsert(La, ++La_len, e); } } }
插入操作 现在考虑加入我们要实现ListInsert(*L, i, e)即在表L的第i个位置插入新元素e,代码应该怎么写?
注意,这里表示变化的集合,所以用指针表示。
我们要先考虑插入思路 :
1 2 3 4 5 如果插入位置不合理,抛出异常 如果线性表长度大于等于数组长度,则抛出异常或者动态增加数组容量。 从最后一个元素开始向前遍历到第i个位置,分别将它们都向后移动一个位置。 最后将要插入到元素填入位置i处。 线性表长度+1。
实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Status ListInsert (SqList *L, int i, ElemType *e) { int k; if (L->length == MAXSIZE) { return ERROR; } if (i < 1 || i > L.length + 1 ) { return ERROR; } if (i <= L->length) { for (k = L->length - 1 ; k >= i-1 ; k--) { L->data[k+1 ]=L->data[k]; } } L->data[i-1 ] = e; L->length++; return OK; }
删除操作 先来看设计思路:
1 2 3 4 判断表长是否为0 首先删除位置要合理,不合理的位置,没有元素,输出异常 删除之后,返回删除的值,用指针变量,被删除元素的后面都要往前补位 列表长度减一
下面来看代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Status ListDelete (SqList *L, int i, int *e) { int k; if (L->length == 0 ) { return ERROR; } if (i < 1 || i >= L->length) { return ERROR; } *e = L->data[i-1 ]; if (i < L->length) { for (k = i; k <= L->length; k++) { L->data[i-1 ] = L->data[i]; } } L->length --; return OK; }
分析插入和删除的时间复杂度 如果两个操作刚好都作用在最后,那么不需要移动任何元素,因此时间复杂度就是O(1)。
最坏的情况:插入和删除的是第一个元素,所有元素都要向后或者向前移动,此时时间复杂度就是O(n)。
所以平均复杂度O((n-1)/2)简化之后也就是O(n)。
顺序存储结构在寸和读的时候都是O(1),在插入删除都是O(n)。
注意啊上述是数组存储结构,也就是顺序存储结构。
优点: 无需为表中元素之间的逻辑关系而增加额外的存储空间。(暗指链式)
可以快速存取表中任意位置的元素。
缺点: 插入和删除操作需要移动大量元素。线性表变化较大时。难以确定存储空间容量,出现空间“碎片”。
原因就在于相邻元素存储位置具有邻居关系,在内存中紧挨着,中间没有间隙。
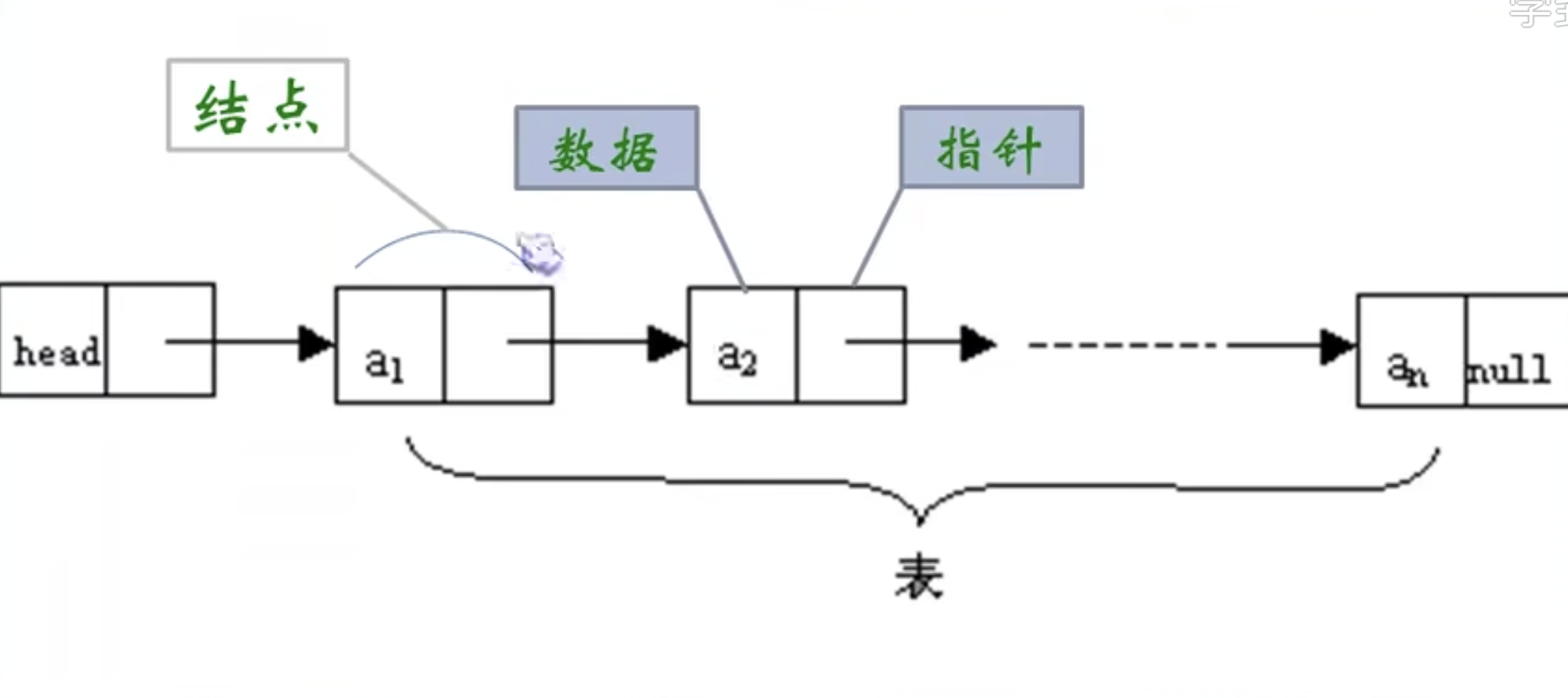
链式存储 存储数据元素信息的域为数据域,存储直接后继位置的为指针域。 指针域中存储的信息称为指针或链。
两部分信息组成数据元素称为存储映像,称为结点(node)。
n个结点链接成一个链表,即为线性表(a1, a2, …, an)的链式存储结构。
因为此链表中的每个结点中只包含一个指针域 ,叫做单链表。
如图所示
头结点和头指针的异同 链表中第一个结点的存储位置叫做头指针 ,最后一个结点的存储指针为空(NULL)。
头结点的数据域一般不存储信息。
头指针是链表指向第一个结点的指针 ,若链表有头结点。
头指针具有标志作用,所以常用头指针冠以链表的名字 (指针变量的名字)。
无论链表是否为空,头指针不为空 ,为空就没有链表了。
头指针是链表的必要元素。
头结点是为了操作的方便和统一而设立的,放在第一个元素的结点之前,数据域一般无意义。(可以放链表的长度)
有了头结点,就方便在第一结点前插入结点和删除结点了。
所以,头结点不是必要的。如图单链表:
如图空链表:
在C语言中用结构指针来描述单链表。
1 2 3 4 5 6 7 8 9 typedef int ElemType;#include "struct_point_to_define.h" typedef struct Node { ElemType data; struct Node * Next ; } Node; typedef struct Node * LinkList ;
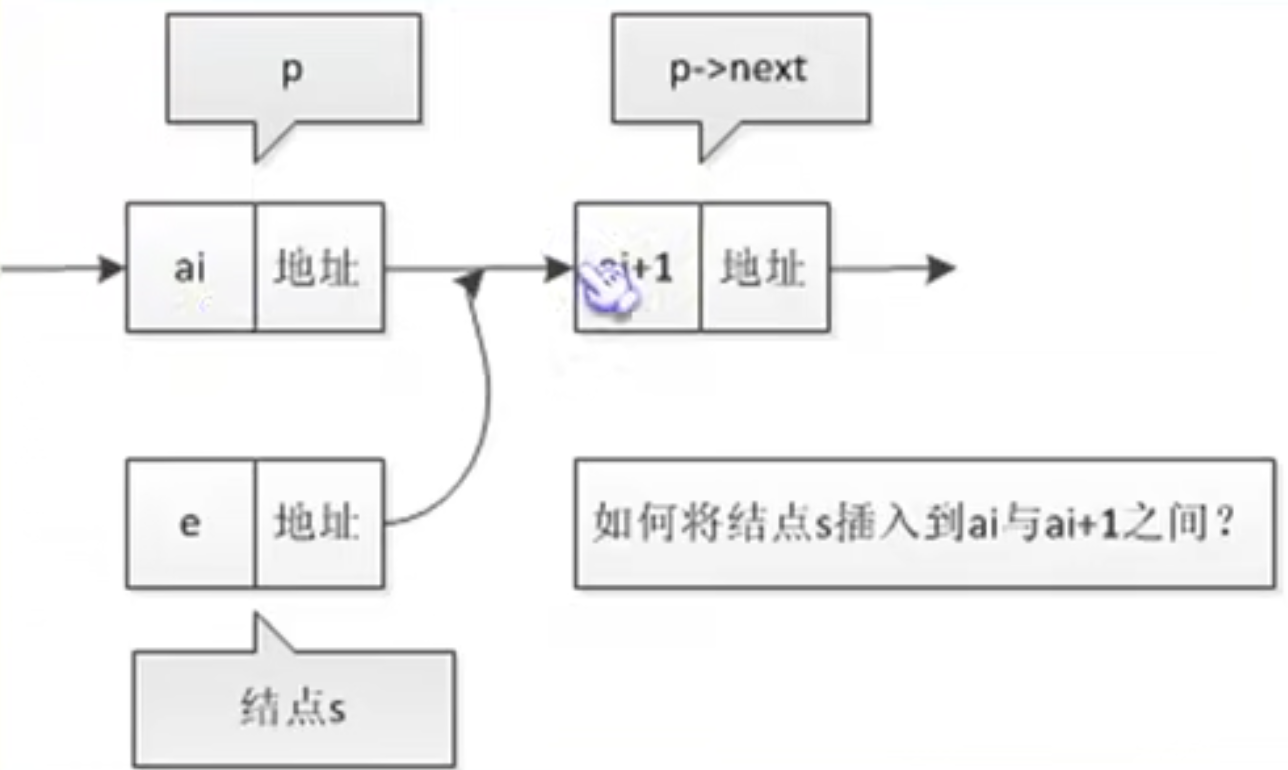
我们可以看到结点由存放数据元素的数据域 和存放后继结点地址的指针域 组成。
举例子: 假设p是指向线性表第i个元素的指针,则该结点ai的数据域我们可以用p->data,其值是一个数据元素,结点ai的指针域可以用p->next来表示,p->next的值是一个指针。
那么p->next指向谁呢,当然是第i+1个元素,也就是指向ai+1的指针。
问题: 如果p->data = ai,那么p->next->data=?其实是下一个结点的数据即ai+1
单链表的读取 第i个元素到底在哪?我们先称其为GetElem。
思路
1 2 3 4 声明一个结点p指向链表第一个结点,初始化j从1开始。p显然是头结点,指向第一个结点。 当j<i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j+1 如果遍历到尾部,p为空,则说明i元素不存在 如果查找成功,就返回结点p的数据。
下面是代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 typedef int ElemType;#define ERROR 0 #define OK 1 typedef struct Node { ElemType data; struct Node * Next ; } Node; typedef struct Node * LinkList ;ElemType GetElem (LinkList L, int i, ElemType *e) { int j; LinkList p; p = L->Next; j = 1 ; while (p && j < i) { p = p->Next; ++j; } if (!p || j>i) { return ERROR; } *e = p->data; return OK; }
复杂度分析
1 2 说白了就是从头开始找找到第i个元素为止。 所以复杂度取决于i的位置,当i=1时,不需要遍历,而i=n时遍历n-1次才可以。所以最坏情况时O(n)
因为没有定义表长,所以用while不用for。其核心思想为工作指针后移。
单链表的插入
每个结点需要两个存储空间分别存储数据和下一个结点的地址。
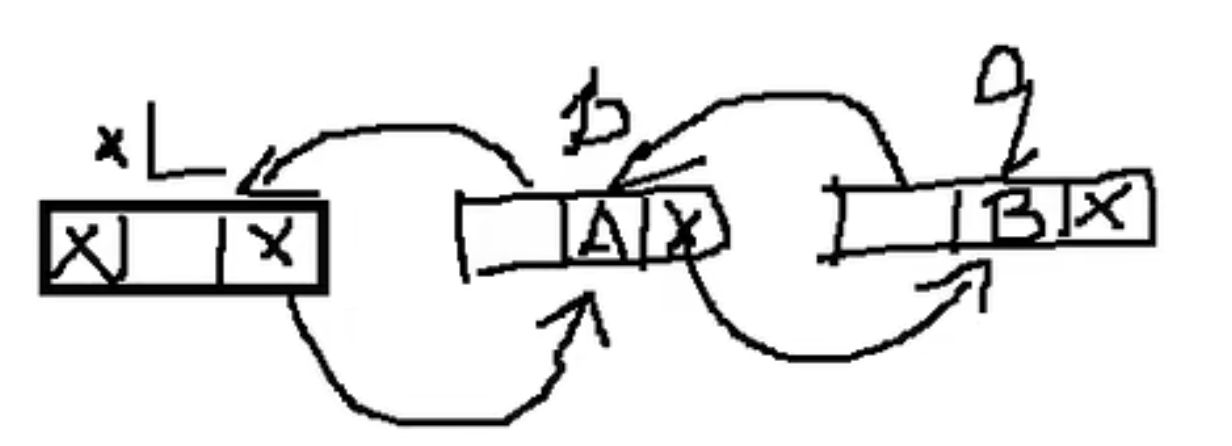
假设存储元素e的结点为s,我们要插入这个结点,如图所示,只需要
1 2 s->next = p->next; p->next = s;
注意不能反过来!反过来下一个结点的地址就会在第一步就丢掉!
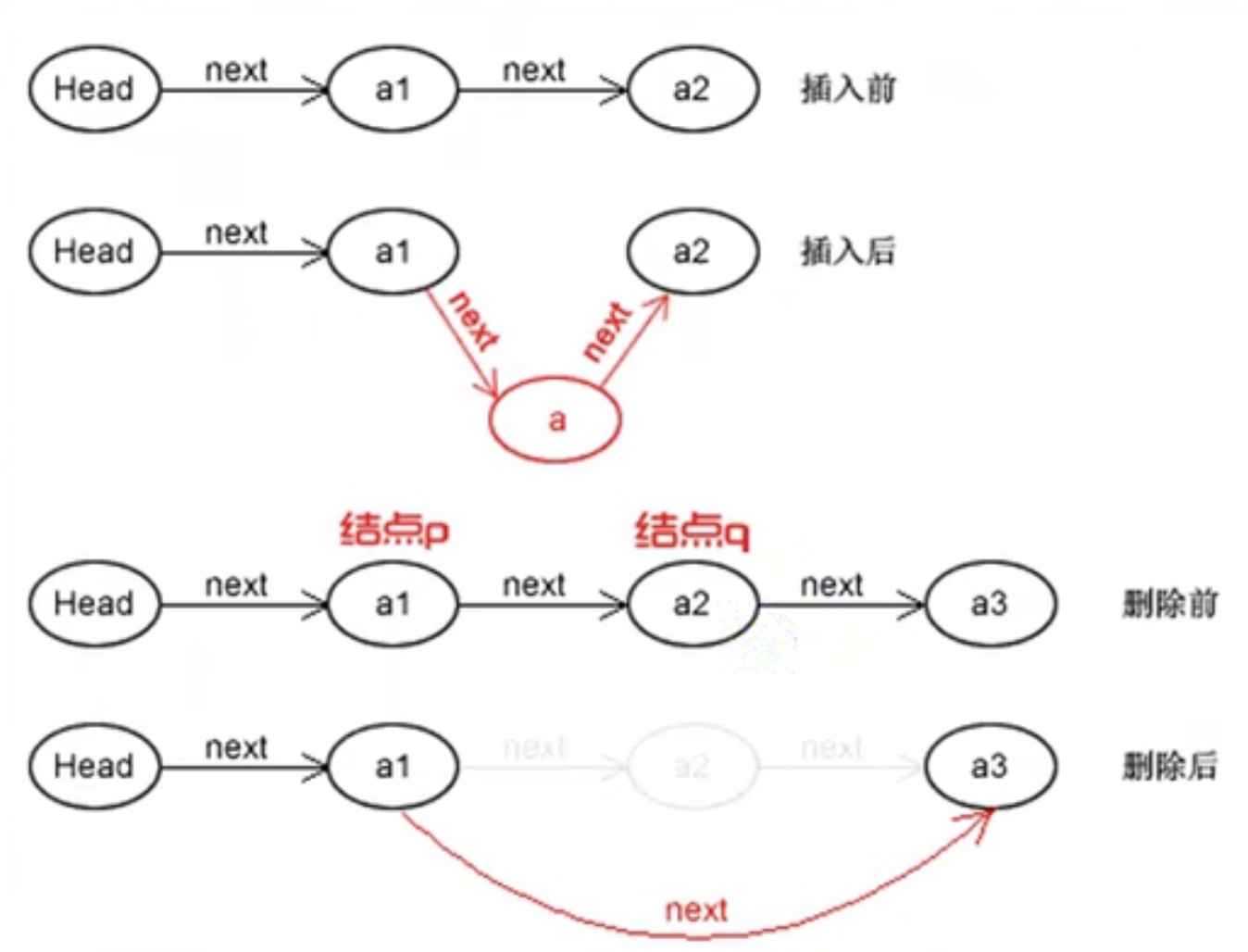
所以,第i个数据插入结点的算法思路:
1 2 3 4 5 声明一结点p指向链表表头结点,初始化j从1开始。 当j<i时,遍历链表,让那个p的指针向后移动,如果到尾部仍然为空,则i不存在,否则i查找成功 查找成功时,在系统生成一个空结点s, 将数据元素e赋值给s->data 单链表的插入用刚才两个标准语句。
详细代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <stdio.h> #include <string> typedef int ElemType;#define ERROR 0 #define OK 1 typedef struct Node { ElemType data; struct Node * Next ; } Node; typedef struct Node * LinkList ;ElemType InsertElem (LinkList L, int i, ElemType e) { LinkList p; p = L->Next; int j; while (p && j < i) { p = p->Next; ++j; } while (!p || j>i) { return ERROR; } LinkList s; s = (LinkList)malloc (sizeof (Node)); s->data = e; s->Next = p->Next; p->Next = s; }
单链表的删除
假设我们要删除结点q,只需要一步即可
1 2 p->next = p->next->next;也就是不指向q即可,直接指向下一个,同时让q指向空即可(省略了) 或者这样一步也行q = p->next;p->next = q->next;
删除结点q算法思路:
1 2 3 4 5 6 声明结点p指向链表第一个结点,初始化j=1 当j<1时,遍历链表,让p的指针向后移动,不断指向下一个结点,j累加1 若到链表末尾为空,则说明第i个元素不存在 否则查找成功,则将欲删除结点p->next赋值给q 将被删除q结点数据赋值给e作为返回。 释放q结点。free函数。
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <string> #include <stdio.h> typedef int ElemType;#define ERROR 0 #define OK 1 typedef struct Node { ElemType data; struct Node * Next ; } Node; typedef struct Node * LinkList ;ElemType DeleteElem (ElemType *e, int i, LinkList *L) { LinkList p; p = *L; int j = 1 ; while (p->Next && j < i) { p = p->Next; ++j; } while (!(p->Next) || j > i) { return ERROR; } LinkList q; q = p->Next; *e = q->data; p->Next = q->Next; free (q); return OK; }
显然,我们分析其算法复杂度,最多为n,都是遍历的过程中实现的。
但是我们如果想在同一个位置插入10个元素,顺序存储结构每一次都需要移动n-i个位置,所以每一次都是O(n)
而我们的单链表只需要找到位置之后,每一次指针赋值即可,都是O(1)。
操作越频繁,单链表效率优势越明显。
单链表的整表创建 对于之前的顺序存储结构,我们对数组初始化 来直观理解。
而单链表和顺序存储结构不一样,它的数据可以分散在各个角落 ,增长也是动态。
对于每个链表来说,其占用空间的大小和位置不需要预先分配划定 的,可以根据系统情况和实际的需求即时生成。
人生就要向单链表一样,随机应变。
创建单链表的过程是一个动态生成链表 的过程,从“空表”的初始状态起 ,依次建立各元素结点并逐个插入链表 。
所以单链表整表创建的算法思路如下:
1 2 3 4 声明结点p和计数器变量i 初始化空链表L 让L的头结点的指针指向Null, 即建立一个带头结点的单链表。 循环实现后继结点的赋值和插入。
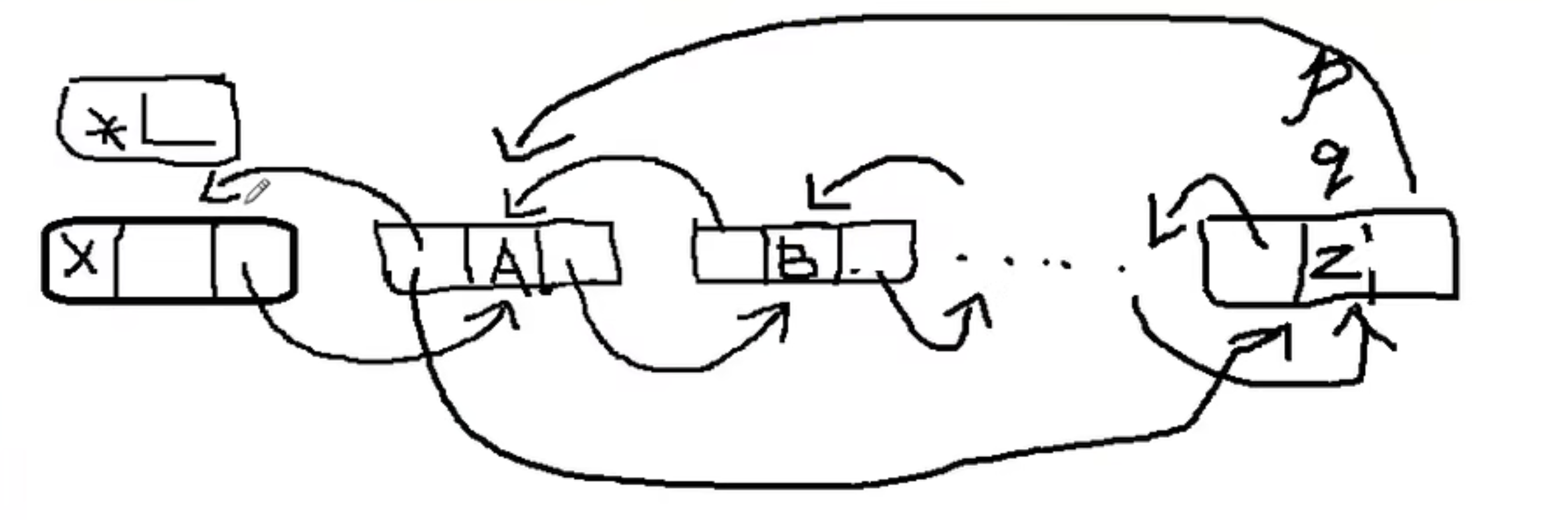
头插法建立单链表 从空表开始,每生成一个新的结点,存储数据之后,将新结点插入到当前链表的表头上,知道结束为止。
先让新结点的next指向头结点,再让表头的next指向新结点。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <string> #include <stdlib.h> #include <stdio.h> #define ERROR 0 #define OK 1 typedef struct Node { int data; struct Node * Next ; } Node; typedef Node* LinkList;void CreateListHead (LinkList *L, int n) { LinkList p; int i; srand(time(0 )); *L = (LinkList) malloc (sizeof (Node)); (*L)->Next = NULL ; for (i = 0 ; i < n; i++) { p = (LinkList) malloc (sizeof (Node)); p->data = rand() % 100 + 1 ; p->Next = (*L)->Next; (*L)->Next = p; } }
尾插法建立单链表 很简单,也就是每一个都插到最后。
代码如下;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <stdio.h> #include <string> #define OK 1 #define ERROR 0 typedef struct Node { int data; struct Node * next ; }Node; typedef struct Node * LinkList ;void CreateListTial (LinkList *L, int n) { LinkList p, r; int i; srand(time(0 )); *L = (LinkList) malloc (sizeof (Node)); r = *L; for (i = 0 ; i < n;i++) { p = (Node *) malloc (sizeof (Node)); p->data = rand()%100 + 1 ; r->next = p; r = p; } r->next= NULL ; }
整表删除 在内存中给它释放掉!
思路
1 2 3 声明结点p和q 将第一个结点赋值给p,下一个结点赋值给q 循环执行释放p和将q赋值给p的操作,然后q再指下一个,循环释放了。
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <stdio.h> #include <string> #define ERROR 1 #define OK 0 typedef struct Node { int data; struct Node * next ; }Node; typedef struct Node * LinkList ;int ClearList (LinkList *L) { LinkList p, q; p = (*L)->next; while (p) { q = p->next; free (p); p = q; } (*L)->next = NULL ; return OK; }
单链表和顺序存储结构优缺点 存储分配: 1 2 顺序存储结构用一段连续的存储单元依次存储线性表的数据元素。 单链表采用链式存储结构,用一组任意的存储单元存放线性表的元素。
时间性能: 1 2 查找:顺序存储O(1),单链表O(n) 插入和删除:顺序存储要平均移动一半多的元素,O(n)。单链表在计算出某位置指针后,插入和删除时间O(1)。
空间性能: 1 2 顺序存储空间需要预先分配 单链表不需要分配存储空间,元素个数不受限制。
如果需要频繁查找,用顺序存储。
如果需要频繁插入,需要单链表结构。
静态链表 古人想出了用数组代替指针描述单链表。因为数组要事先声明,无法改变。
代码如下:
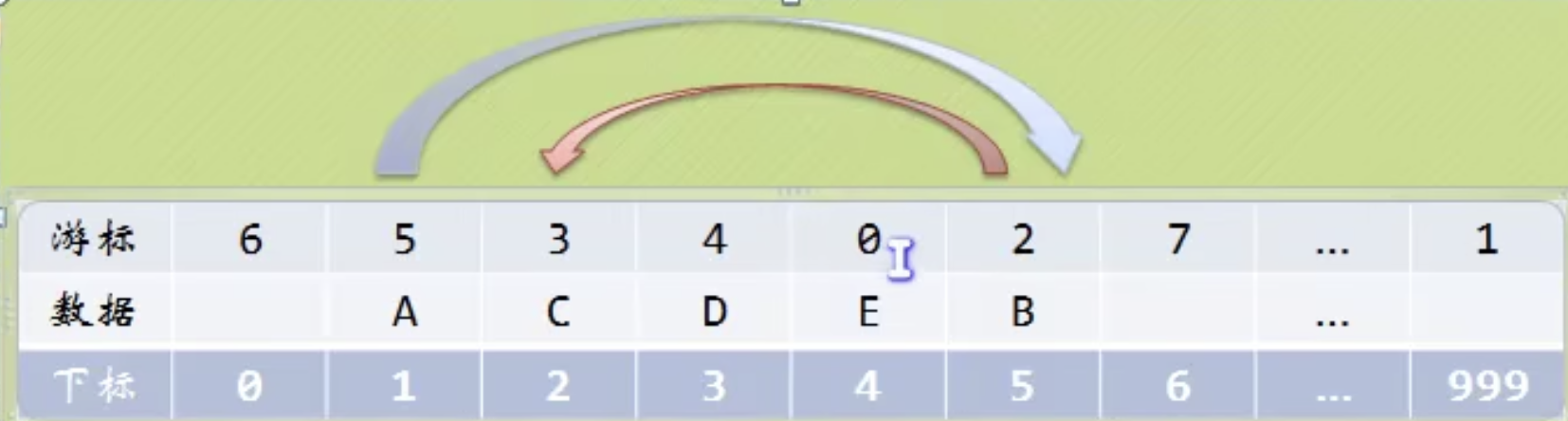
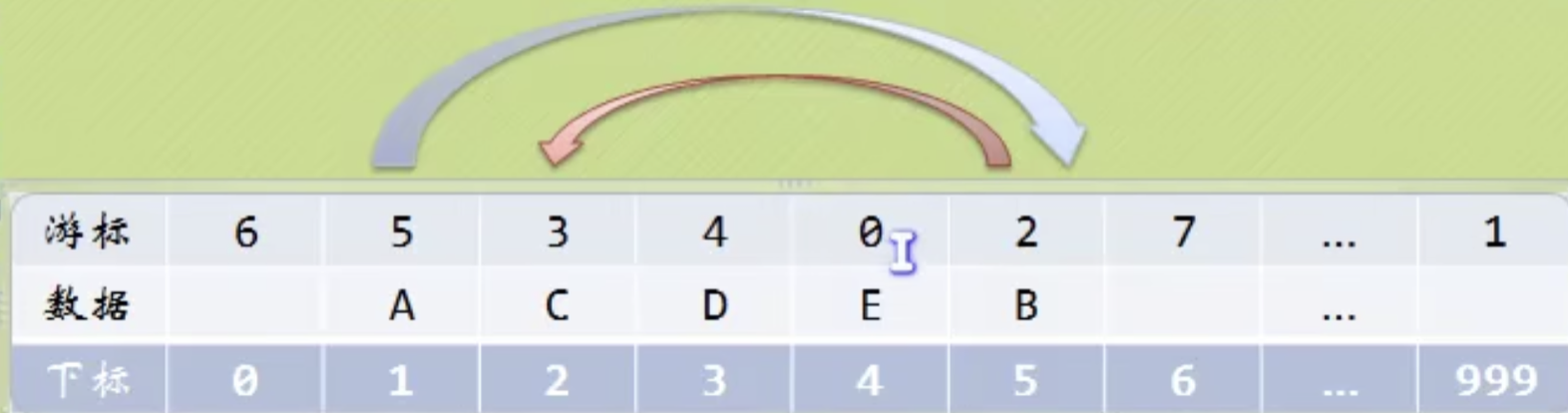
第一个元素是不存放东西的,最后一个数组的位置也是不存放的。
我们可以看到,第一个元素的游标,指向了第二个元素的下标 。第二个元素的游标3,指向了第三个元素D的下标3。这就和单链表很像了。
我们对数组的第一个和最后一个元素做特殊处理 ,他们的data不存放数据 。
我们通常把未使用的数组元素称为备用链表 。
数组的第一个元素,即下标为0 元素的cursor 就存放备用链表的第一个结点的下标 ,即链接到备用链表。
数组的最后一个元素,即下标为MAXSIZE-1 的元素的cursor 存放第一个有数值的元素的下标 ,相当于单链表中的头结点作用。相当于把数据链接起来。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #define MAXSIZE 1000 #define OK 1 typedef struct { int data; int cur; }Component, StaticLinkList[MAXSIZE]; int InitList (StaticLinkList space) { int i; for (i = 0 ; i < MAXSIZE - 1 ; i++) { space[i].cur = i + 1 ; } space[MAXSIZE - 1 ].cur = 0 ; return OK; }
静态链表中操作的是数组,不存在动态链表中结点的malloc申请和free释放的问题,所以我们需要自己实现申请者两个函数,达到插入和删除。
静态链表的插入操作 如图所示
也就是把B放到了E的后面,但是注意,我们想插入它到第二个元素,第一个元素是A ,A的游标指向第二个元素,所以将A的游标指向5,也就是存放B ,将B的游标指向2,也就是存放C ,这样就插进去了。
我们来看代码,两部分组成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 int Malloc_SLL (StaticLinkList space) { int i = space[0 ].cur; if (space[0 ].cur) { space[0 ].cur = space[i].cur; } return i; } int InsertList (StaticLinkList L, int i, int e) { int j, k, l; k = MAXSIZE - 1 ; if (i < 1 || i > ListLength(L) + 1 ) { return ERROR; } j = Malloc_SLL(L); if (j) { L[j].data = e; for (l = 1 ; l <= i-1 ; l++) { k = L[k].cur; } L[j].cur = L[k].cur; L[k].cur = j; } }
静态链表的删除操作 如图所示,删除C元素之前
删除C元素之后:
可以看出我们B不再指向C而是指向D也就是B的游标改为C的游标是3,其实就是链表中的赋值操作。
并且我们将E也就是最后一个元素指向开头,这是约定俗成的,不变。
因为我们知道开头位置是用来指向第一个空 位置的,所以先将B的游标改为原来开头的游标6,再将开头的游标改为2(原来B的位置),也就是链表的操作。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int DeleteList (StaticLinkList L, int i) { int j, k; if (i < 1 || i > ListLength(L)) { return ERROR; } k = MAXSIZE - 1 ; for (j = 1 ; j <= i - 1 ; j++) { k = L[k].cur; } j = L[k].cur; L[k].cur = L[j].cur; Free_SLL(L, j); return OK; } void Free_SLL (StaticLinkList space, int j) { space[j].cur = space[0 ].cur; space[0 ].cur = j; }
获取链表长度代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 int ListLength (StaticLinkList L) { int j = 0 ; int i = L[MAXSIZE - 1 ].cur; while (i) { i = L[i].cur; j++; } return j; }
总结 优点:插入和删除只需要修改游标,不需要移动元素,从而改进了顺序存储中插入和删除时需要移动大量元素的缺点。
缺点:没有解决连续存储分配(数组需要的)带来的表长难以确定问题。并且不能随机存取。
这是为了没有指针的编程语言的单链表方法(其实很鸡肋)
面试题 快速找到未知长度单链表的中间节点。
首先我们需要遍历一遍单链表以确定长度L,也就是访问一个就让一个变量加一下。
然后再从头结点出发循环L/2次找到中间节点。
复杂度也就是L + L/2。
快慢指针原理: 设置两个指针search, mid都指向头节点。其中*search的移动速度是*mid的两倍。当*search指向末尾节点的时候,mid就刚好在中间了。这是标尺的思想。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <string> #include <stdio.h> #define OK 1 typedef struct Node { int data; struct Node * next ; }Node; typedef struct Node * LinkList ;int get_mid_node (LinkList L, int *e) { LinkList search, mid; mid = search = L; while (search->next != NULL ) { if (search->next->next != NULL ) { search = search->next->next; mid = mid->next; } else { search = search->next; } } *e = mid->data; return OK; }
课后作业的答案代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <string> #include <stdio.h> #include <math.h> #define OK 1 typedef struct Node { int data; struct Node* next; }Node; typedef struct Node* LinkList; int get_mid_node(LinkList L, int *e) { LinkList search, mid;//定义两个指针同时开始跑,一个1一个一次跑两下 mid = search = L;//L表示链表头部 while (search->next != NULL) { if(search->next->next != NULL) { search = search->next->next; mid = mid->next; } else { search = search->next; } } *e = mid->data; return OK; } void CreateListTail(LinkList *L, int n) { LinkList p, r; int i; srand(time(0)); *L = (LinkList) malloc(sizeof (Node));//创建链表 r = *L;//尾指针 for(i = 0;i < n;i++) { p = (Node*) malloc(sizeof (Node));//逐个创建结点 p->data = rand()%100 + 1;//给出数据,rand()返回0和RAND_MAX之间的整数,是一个伪随机数 r->next = p;//也就是尾插法; r = p;//转移尾指针 } r->next = NULL;//最后一个指向空。 } void PrintList(LinkList L) { LinkList p;//定义指针,就不用分配空间 for(p = L; p->next != NULL; p = p->next) { printf("%d\n", p->data); } } int main() { int n; int *mid_value; scanf("%d", &n);//输入链表长度 LinkList *L; CreateListTail(L, n); PrintList(*L);//输出链表 get_mid_node(*L, mid_value); printf("%d\n", *mid_value); return 0; }
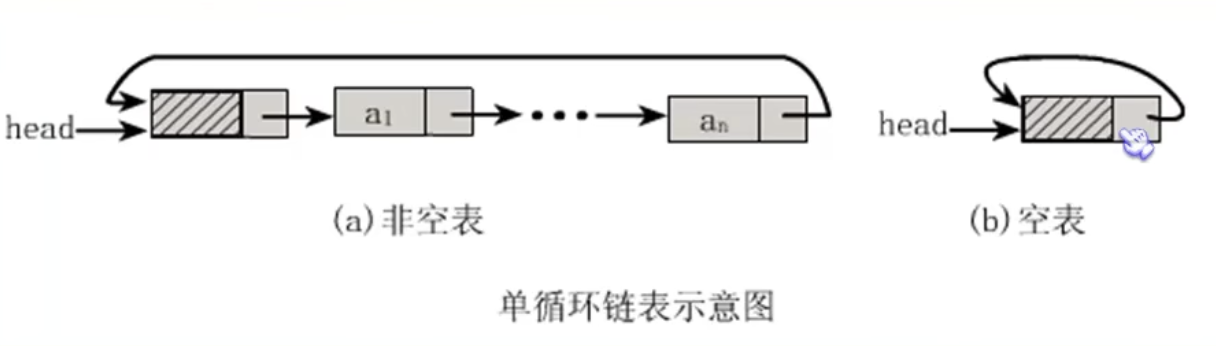
循环链表 事实上我们只需要将单链表中终端指针由空指针改变为指向头结点,就没问题了。
使得整个单链表形成一个环,头尾相接的单链表,成为单循环链表。
两种情况如图所示,哪怕是空表,也要有自己指向自己,成为循环。
其实循环链表与单链表主要差异在于判断空链表的条件上,原来判断head->next是否为null,现在则是head->next是否等于head。终端结点指针用rear表示,查找终端结点是O(1),而开始结点是rear->next->next,当然也是O(1)。
下面代码是实现初始化链表,插入数据,删除数据和搜索数据等函数的代码集合:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 #include <stdio.h> #include <string> typedef struct Node { int data; struct Node * next ; }node; void ds_init (node **pNode) { int item; node *temp; node *target; printf ("输入结点的值,输入0完成初始化\n" ); while (1 ) { scanf ("%d" , &item); fflush(stdin ); if (item == 0 ) return ; if ((*pNode) == NULL ) { *pNode = (node*) malloc (sizeof (struct Node)); if (!(*pNode)) exit (0 ); (*pNode)->data = item; (*pNode)->next = *pNode; } else { for (target = (*pNode); target->next != (*pNode); target = target->next) ; temp = (node*) malloc (sizeof (struct Node)); if (!temp) exit (0 ); temp->data = item; temp->next = *pNode; target->next = temp; } } } void ds_insert (node **pNode, int i) { node *temp; node *target; node *p; int item; int j = 1 ; printf ("输入要插入结点的值:" ); scanf ("%d" , &item); if (i == 1 ) { temp = (node*) malloc (sizeof (struct Node)); if (!temp) exit (0 ); temp->data = item; temp->next = (*pNode); for (target = (*pNode); target->next != (*pNode); target = target->next) ; target->next = temp; *pNode = temp; } else { target = *pNode; for (; j < (i-1 ); ++j) { target = target->next; } temp = (node*) malloc (sizeof (struct Node)); if (!temp) exit (0 ); temp->data = item; p = target->next; target->next = temp; temp->next = p; } } void ds_delete (node **pNode, int i) { node *target; node *temp; int j = 1 ; if (i == 1 ) { for (target = *pNode; target->next != *pNode; target = target->next) ; temp = *pNode; *pNode = (*pNode)->next; target->next = *pNode; free (temp); } else { target = *pNode; for (; j < (i-1 ); ++j) { target = target->next; } temp = target->next; target->next = target->next->next; free (temp); } } int ds_search (node *pNode, int elem) { node * target; int i = 1 ; for (target = pNode; target->data == elem && target->next != pNode; ++i) { target = target->next; } if (target->next == pNode && target->data != elem) return 0 ; else return -1 ; }
约瑟夫问题 这个问题,在密码学的排列问题中也出现了,我们在密码代数中讨论的是排列循环问题,在这里则
下面通过编写循环链表,给出自杀的人的编号。
下面是代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <stdio.h> #include <string> typedef struct Node { int data; struct Node * next ; }Node; typedef struct Node * LinkList ;LinkList Create (int n) { LinkList p = NULL ; LinkList head; head = (LinkList) malloc (sizeof (struct Node)); p = head; LinkList s; int i = 1 ; if (0 != n) { while (i <= n) { s = (LinkList) malloc (sizeof (struct Node)); s->data = i++; p->next = s; p = s; } s->next = head->next; } free (head); return s->next; } int main () { int n = 41 ; int m = 3 ; int i; LinkList p = Create(n); LinkList temp; m %= n; while (p != p->next) { p = p->next; printf ("%d->" , p->next->data); temp = p->next; p->next = temp->next; p = p->next; free (temp); } printf ("%d\n" , p->data); return 0 ; }
循环链表特点 有了头结点时,访问第一个结点用O(1)的时间,访问最后一个需要O(n)的时间。
也就是无需增加存储量,通过灵活改变链接方式,就可以得到很好的处理。
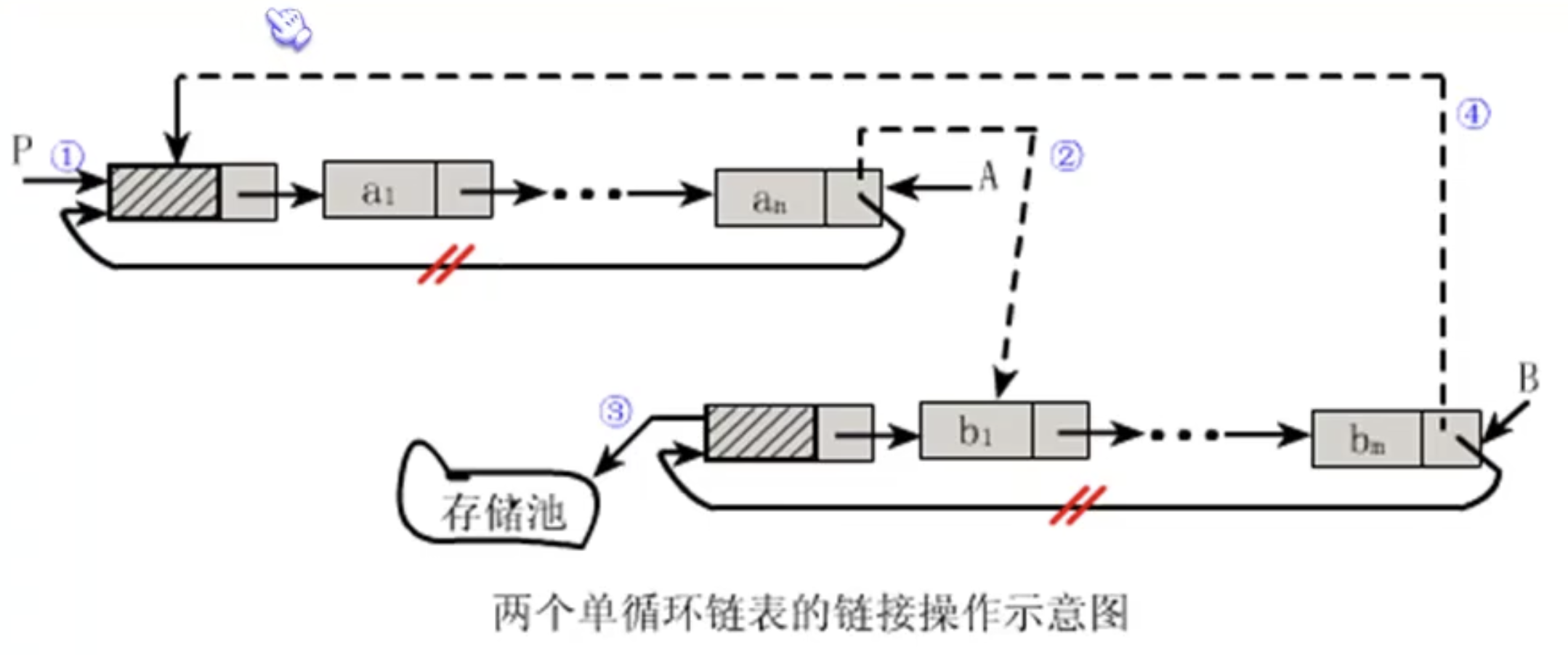
比如链接两个链表!
1.若在单链表或者头指针表示的单链表循环上做这种链接,我们只需要遍历到an然后将b1链接到an后面!执行时间为O(n)
2.若在尾指针表示的单循环链表上实现,则只需要修改指针,无需遍历,时间O(1)。
可以看到,链接到b链表以后,把b的头结点可以扔掉了,因为一个链表只需要一个头结点。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> #include <string> typedef struct Node { int data; struct Node * next ; }Node; typedef struct Node * LinkList ;LinkList Connect (LinkList A, LinkList B) { LinkList p = A->next; A->next = B->next->next; free (B->next); B->next = p; return B; }
通常我们用头插法创建无环链表,尾插法创建有环链表。
判断单链表中是否有环 有环的定义:链表的尾结点指向了链表中的某个节点。
方法一:使用p, q两个指针,p总是向前走,但q每次都从头开始走,对于每个节点,看p走的步数是否和q一样。如图,当p从6走到3时,用了1步,此时若从q出发,用了两步,步数不相等了,存在环。
方法二:使用p, q两个指针,p每次向前走一步,q每次向前走两步,若在某个时候p==q,则存在环。
代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #define OK 1 #include <string> #include <stdio.h> typedef struct Node { int data; struct Node * next ; }Node; typedef struct Node * LinkList ;int HasLoop1 (LinkList L) { LinkList cur1 = L; int stp1 = 0 ; while (cur1) { LinkList cur2 = L; int stp2 = 0 ; while (cur2) { if (cur2 == cur1) { if (stp1 == stp2) break ; else { printf ("The position of loop is in the %d node\n\n" , stp2); return 1 ; } } cur2 = cur2->next; stp2++; } cur1 = cur1->next; stp1++; } return 0 ; }
用快慢指针判断 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int HasLoop2 (LinkList L) { int step1 = 1 ; int step2 = 2 ; LinkList p = L; LinkList q = L; while (p != NULL && q != NULL && q->next != NULL ) { p = p->next; if (q->next->next !=NULL ) q = q->next->next; printf ("p:%d, q:%d\n" , p->data, q->data); if (p == q) return 1 ; } return 0 ; }
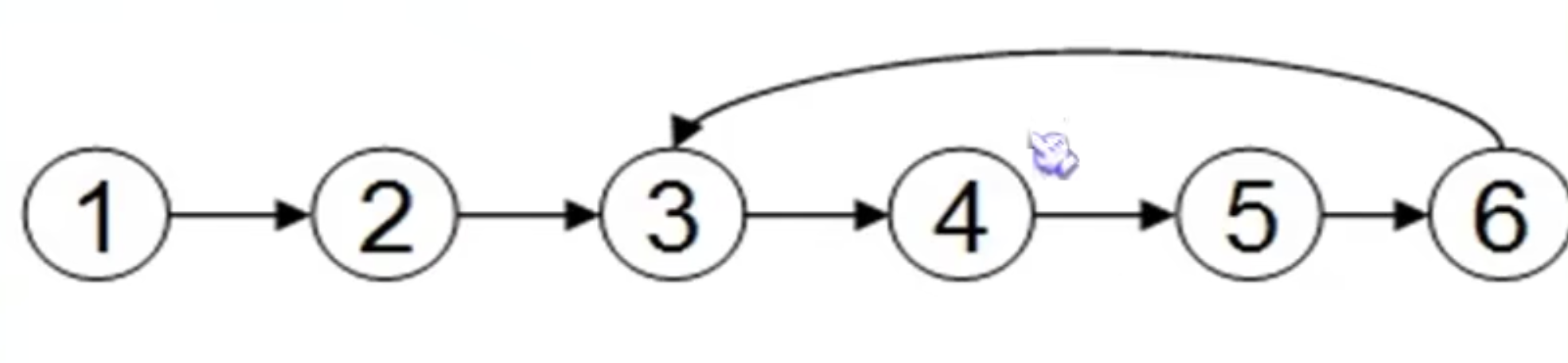
魔术师发牌问题 一个很简单的问题,先抽一张牌,保证正好是1,放最后。然后再抽两张牌,第一张放最后,第二张保证是2,放最后。然后再抽三张牌,第一二张放最后,第三张保证为3。用循环链表来实现吧!
图片示例如下:
初始化
执行完两次for循环之后,赋值之后
当第一行1234都被赋值过后,也就是如图所示
4再向下应该找5个,并且再向下的第5个位置数据为5。此时已经遍历回来了。当遍历到1时,也就是p->data != 0
1 因为回到1的时候,1这个牌已经被抽走放下面去了,所以应该不算这次,故用j--抵消j++的自增。同时p向后一个
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 #include <string> #include <stdio.h> #include <math.h> #define CardNumber 13 typedef struct Node { int data; struct Node * next ; }Node; typedef struct Node * LinkList ;LinkList CreateLinkList () { LinkList head = NULL ; LinkList s, r; int i; r = head; for (i = 1 ; i <= CardNumber; i++) { s = (LinkList) malloc (sizeof (struct Node)); s->data = 0 ; if (head == NULL ) head = s; else r->next = s; r = s; } r->next = head; return head; } void Magician (LinkList head) { LinkList p; int j; int Countnumber = 2 ; p = head; p->data = 1 ; while (1 ) { for (j = 0 ; j < Countnumber; j++) { p = p->next; if (p->data != 0 ) { p = p->next; j--; } } if (p->data == 0 ) { p->data = Countnumber; Countnumber++; if (Countnumber == 14 ) break ; } } } void DestoryList (LinkList* list ) { } int main () { LinkList p; int i; p = CreateLinkList(); Magician(p); printf ("按如下顺序排列:\n" ); for (i = 0 ; i < CardNumber; i++) { printf ("黑桃%d" , p->data); p = p->next; } DestoryList(&p); return 0 ; }
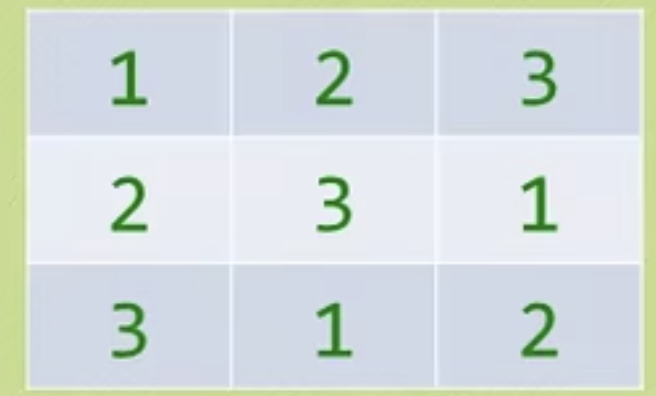
拉丁方阵问题
其实就像数独!同样用循环链表来解决!比如n=3时,我们可以打印如下
只需要一行一行打印,下一行向后错一个即可!
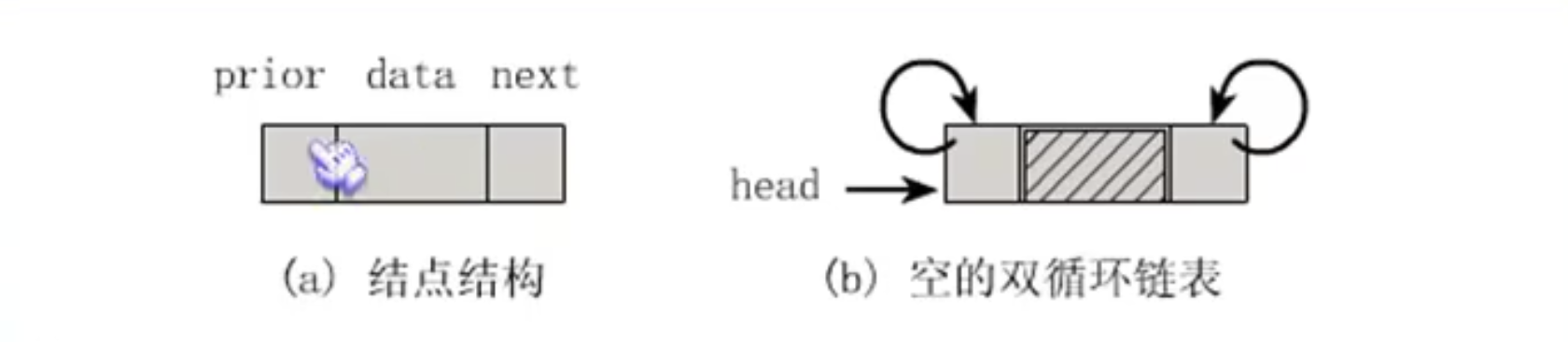
双向链表 比如我们的铁路,一定设计成双向的,从A到B到C,比如从B想去A就可以直接B->A而不是通过环B->C->A很麻烦。所以双向链表很重要。
结点结构 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> #include <string> typedef struct DualNode { int data; struct DualNode *prior ; struct DualNode * next ; }DualNode; typedef struct DualNode * DuLinkList ;
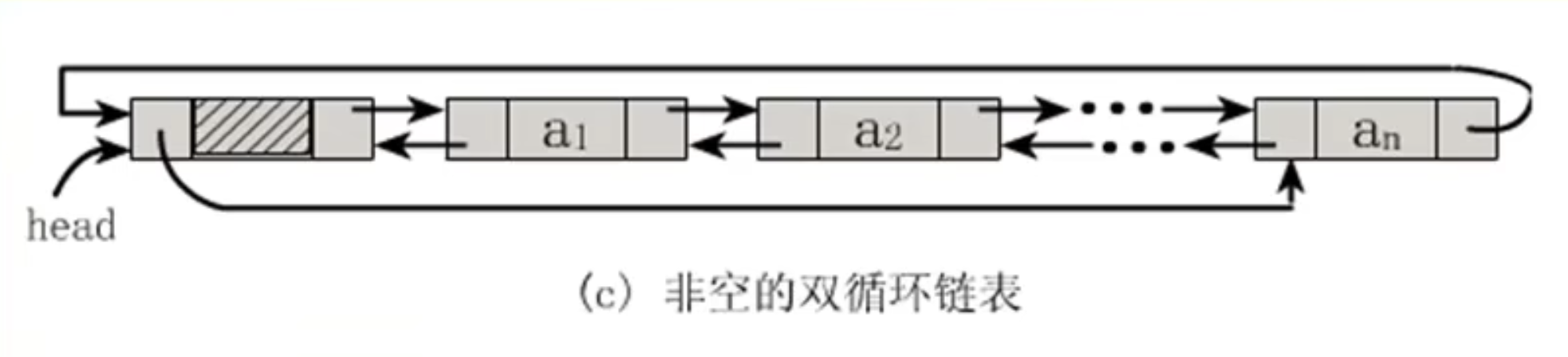
可以看到也就是在每个结点多了一个域,指向后面的。并且可以看到空链表的双循环链表。
下图是非空的双循环链表。
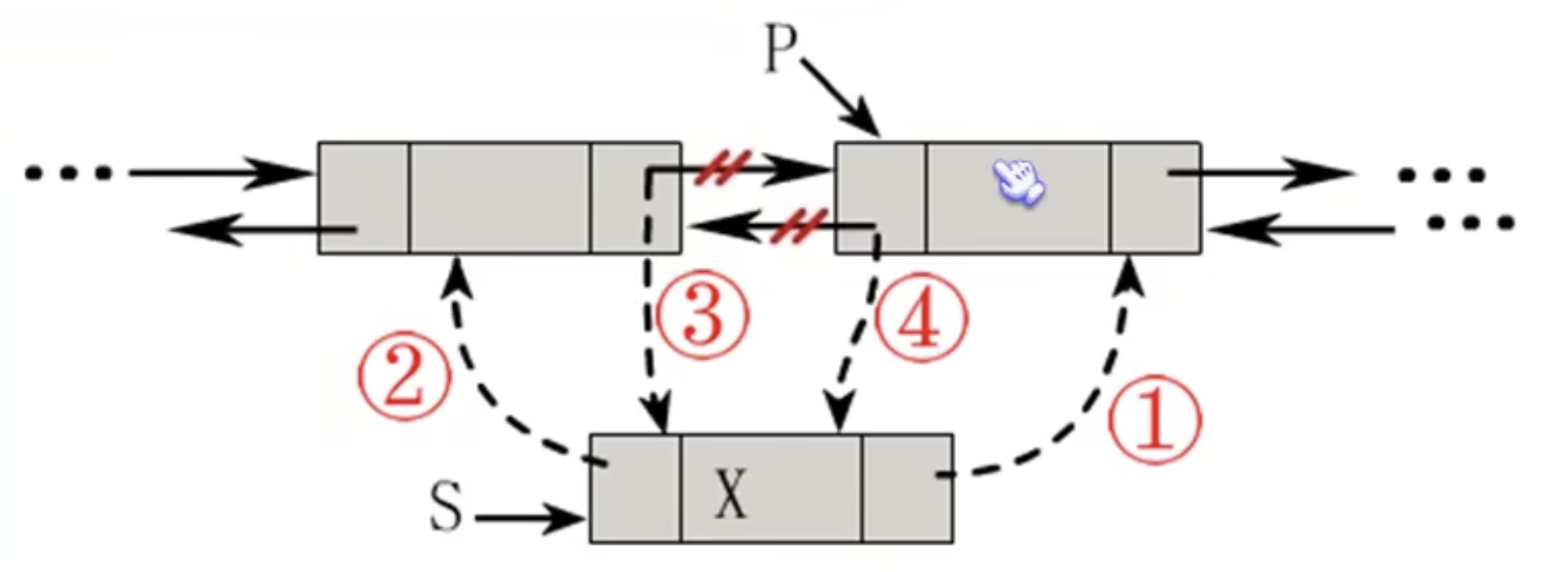
双向链表的插入操作 如图所示
代码实现,注意图中画的箭头(1)的部分应该指在P结点中间,箭头有些歪了。
1 2 3 4 s->next = p; s->prior = p->prior;#也就是先把新结点的箭头都钩上,再将其插进原来两个结点中间去。 p->prior->next = s; p->prior = s;
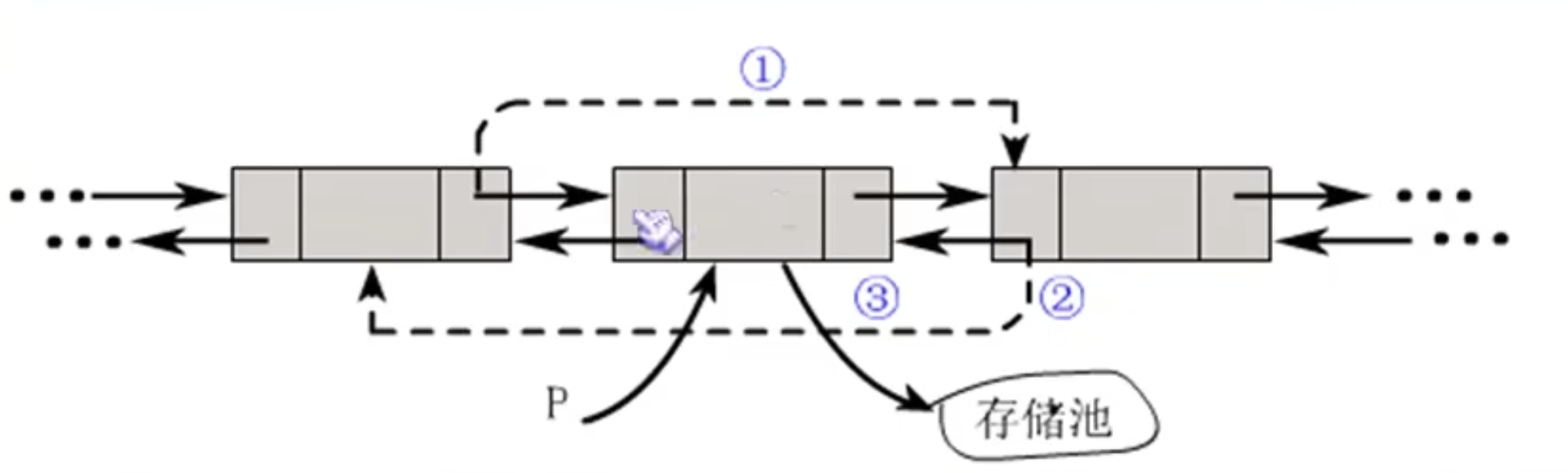
双向链表的删除操作
如图所示,我们也是先将两个最后要链接在一起的结点连到一起,之后再释放中间的结点,这样不会出错。
代码如下:
1 2 3 p->prior->next = p->next;#把上一个连给下一个 p->next->prior = p->prior;#把下一个连回上一个 free (p);#释放中间的
双向循环链表实践 要求实现用户输入一个数使得26个字母的排列发生变化,比如用户输入3,输出结果:
DEFG…..ABC
同时需要支持负数,比如用户输入-3,输出结果
XYZABC….UVW
下面开始从0实现,如图所示。
我们可以看出,生成的时候,每生成一个新结点,就
代码如下:生成B的时候
1 2 3 4 q->prior = p; q->next = p->next; p->next = q; p = q;一直循环下去就可以生成链表
我们只需要用p, q两个指针循环生成即可。
全部代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 #include <string> #include <stdio.h> #define OK 1 #define ERROR 0 typedef char ElemType;typedef int Status;typedef struct DualNode { ElemType data; struct DualNode *prior ; struct DualNode *next ; }DualNode, *DuLinkList; Status InitList (DuLinkList *L) { DualNode *p, *q; int i; *L = (DuLinkList ) malloc (sizeof (struct DualNode)); if (!(*L)) return ERROR; (*L)->next = (*L)->prior = NULL ; p = (*L); for (i = 0 ; i < 26 ; i++) { q = (DualNode*) malloc (sizeof (struct DualNode)); if (!q) return ERROR; q->data = 'A' + i; q->prior = p; q->next = p->next; p->next = q; p = q; } p->next = (*L)->next; (*L)->next->prior = p; return OK; } void Caesar (DuLinkList *L, int i) { if (i > 0 ) { do { (*L) = (*L)->next; }while (--i); } if (i < 0 ) { do { (*L) = (*L)->prior; }while (++i); } } int main () { DuLinkList L; int i, n; printf ("请输入一个整数;" ); scanf ("%d" , &n); printf ("\n" ); InitList(&L); Caesar(&L, n); for (i = 0 ; i < 26 ; i++) { L = L->next; printf ("%c" , L->data); } return 0 ; }
因为要实现循环链表,在上面双向链表的基础上,就要将尾结点指向第二个结点,也就是next指过去,再将第二个结点的prior指回末尾,代码也在上面,如图所示,因为
在这里头结点是没有元素的,参加循环可能输出奇怪的值,没有必要。
课后作业














 wechat
wechat