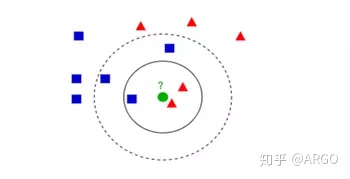
#我们假设dataset是二维数组,每个向量之中两个分量,第一个表示类别比如红色,第二个表示值。 int a#待定点 dataset.reshape(-1, 2)#也就是修改成列向量的形式。 for i in range(dataset): to_each_sample_distance[i][1] = distance(a, dataset(i)(1)) to_each_sample_distance[i][0] = dataset(i)(0)#把类别也归进去 k = 5 for i in range(to_each_sample_distance): for j in i: if(to_each_sample_distance[j][1] > to_each_sample_distance[j+1][1]): swap(to_each_sample_distance[j], to_each_sample_distance[j+1])用冒泡排序把小的放前面 count = [[0, 0] * 100]#因为最多也不会有很多类,每个类对应其个数 for i in range(5): if to_each_sample_distance[i][0]: count[i][0] = to_each_sample_distance[i][0] count[i][1]++#个数+1 count.reshape(-1, 2)#转化为列向量 max = [0, 0] for i in range(count)-1: if count[i][1] > count[i+1][1] max[1] = count[i][1] max[0] = count[i][0] print(max[0])#即为我们最后判定的类。

 wechat
wechat