
ocr笔记
传统OCR系统最重要的步骤就是特征提取,为了找出图像候选的文字区域的特征。特征提取第一步是特征设计,特征设计是非常麻烦的事情,需要大量人工对汉子的独有结构进行特征设计,并且做分类数据库。
下面是传统OCR计数框架图。
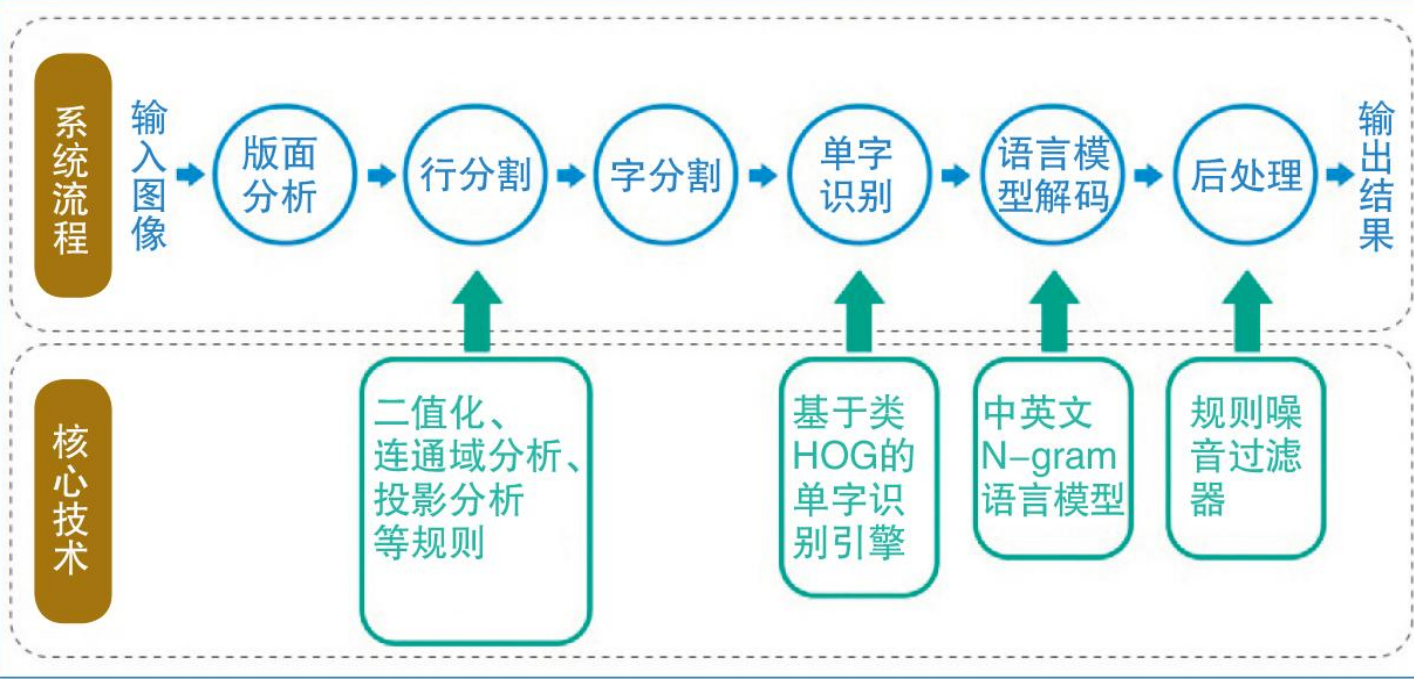
并且,用人工设计的特征来训练字符识别模型,单一的特征在字体发生变化时,泛化能力显著下降,鲁棒性不够。它还非常依赖最后字符分割的结果,所以错误率很高。
在ocr识别系统中,所有步骤被大致分成了三个部分。首先是图像输入预处理,然后是图像分割,然后是汉字识别,当然也包括英文等其他识别,最后对识别结果进行处理。
图像预处理时,为了加快图像识别模块的处理速度,需要将彩色图像转换为灰度图像,减小图像矩阵占用的内存空间。由彩色图像转换为灰度图像的过程叫做灰度化处理,灰度图像就是只有亮度信息而没有颜色信息的图像,而且存储灰度图像只需要一个数据矩阵,矩阵中的每个元素都表示对应位置像素的灰度值。
通过拍摄,扫描等方式采集图像可能会有局部区域模糊,对比度偏弱等因素的影响,而图像增强可以用于图像对比度的调整,可以突出图像的重要细节!因此,采用图像灰度变换等方法可以有效增强图像对比度,提高图像中字符的清晰度。
对比度增强是典型的空域图像增强算法,这种处理只是逐点修改原始图像中每个像素的灰度值,不会改变图像中像素的位置,在输入像素与输出像素之间是一对一的映射关系。
图像可能在扫描过程中受到噪声干扰,为了提高识别模块的准确率,通常采用平滑滤波的方法(中值滤波,均值滤波)去噪。
一旦图像被定义为一种数据类型,并能够访问该图像的灰度值(即像素),我们用直方图来表示不同灰度的概率密度函数。图像直方图表示图像中各种灰度出现的频率。可以对直方图建模,使图像可以改变其对比度,被称为直方图均衡化(histogram equalization)。直方图建模对于以对比度变化的方式进行图像增强是一种非常有用的技术。直方图均衡化允许低对比度的图像区域获取更高的对比度。
5.10.2 OCR 实现自然图像中文本的识别
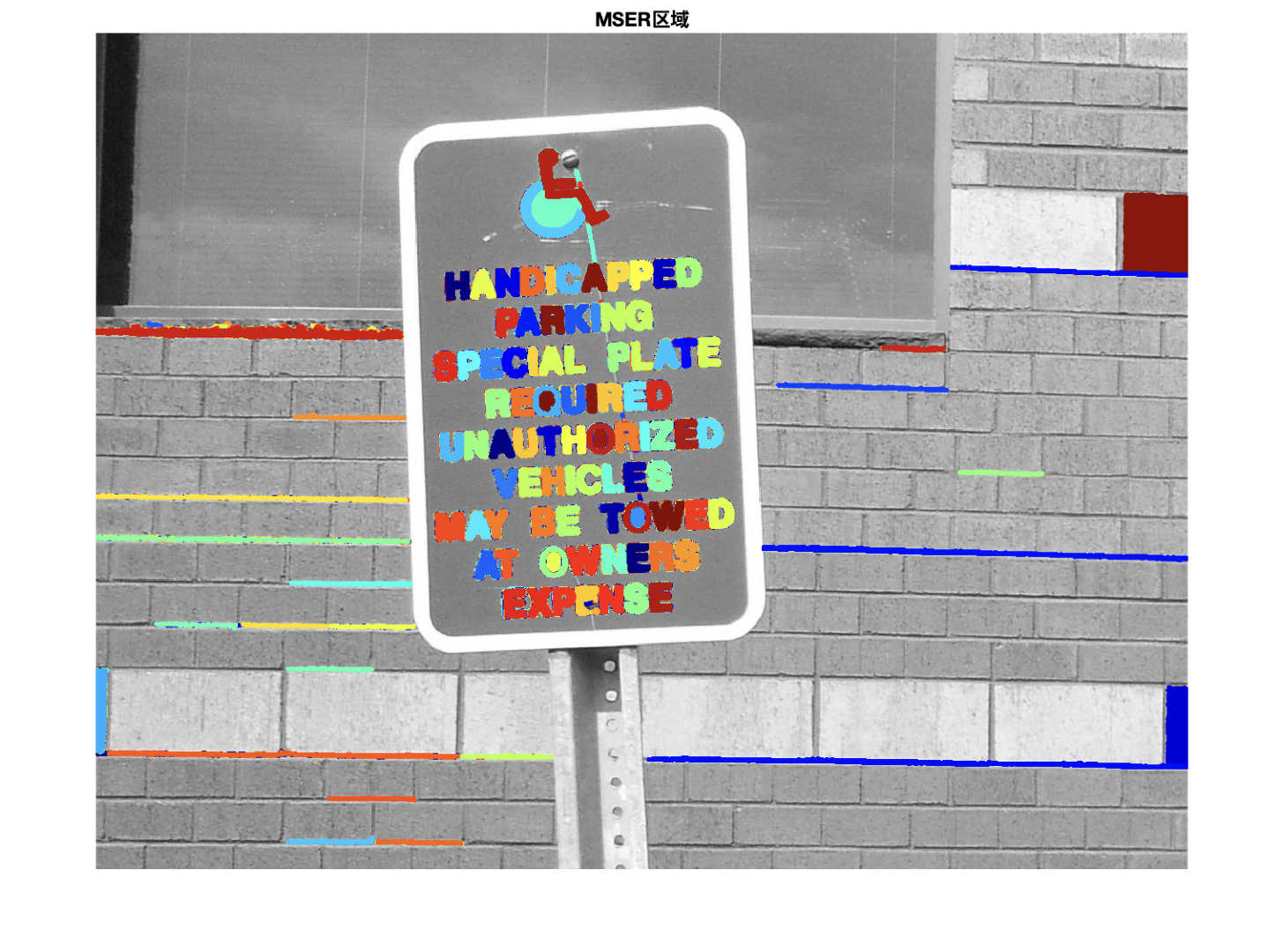
1.使用MSER检测器候选文本区域
这种检测器可以很好的找到文本区域。它适用于文本,因为文本是具有一致的颜色和高对比度,是一种稳定的强度配置文件。
MSER(Maximally Stable Extremal Regions)区域是图像处理和计算机视觉中的一种特征,用于检测和描述图像中的稳定区域。这些稳定区域通常具有以下特点:
稳定性:MSER区域是稳定的,这意味着它们在不同尺度和光照条件下都能保持相对不变。这使它们适合用于物体检测、跟踪和匹配等计算机视觉任务,因为它们对图像变化具有一定的鲁棒性。而文本是在图像中稳定的区域。
区域性质:MSER区域是连通的像素集合,通常表示图像中的一个区域或物体。它们可以是图像中的明亮或暗区域,具体取决于应用的背景和需求。文本通常以连通的形式存在于图像中。
灰度值稳定性:MSER区域的灰度值变化相对较小,因此它们在灰度值上具有一定的一致性。而文本通常以相对一致的灰度值显示在图像中。
区域的最大性:MSER区域是在满足一定条件下,具有最大稳定性的区域。这意味着它们在变化尺度下会保持不变,并且不会被更大或更小的区域完全包含。
MSER区域检测通常用于对象检测、图像分割、文字检测和物体跟踪等计算机视觉任务中。它们可以帮助识别图像中的显著区域,进而用于后续的分析和处理。MSER检测器在MATLAB等图像处理工具中提供了一种方便的方式来自动检测这些稳定区域。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18%使用detectMSERFeatures函数找到图像中所有区域并且绘制这些结果。
%需要注意,它会在文本旁边检测到许多非文本区域
colorImage = imread('handicapSign.jpg');
I = rgb2gray(colorImage);%先转成灰度图像
%MSER检测区域
[mserRegions, mserConnComp] = detectMSERFeatures(I, 'RegionAreaRange', [200, 8000], 'ThresholdDelta', 4);
%RegionAreaRange指定要保留的MSER区域的面积范围。因为MSER将图像分割成许多不同的区域,每个区域都是一组连通的像素。这些区域的大小可以有很大的差异。
%[200, 8000]分别为最小最大面积条件,即MSER的面积至少为200像素,面积<200像素的MSER区域就会被过滤掉。有助于消除图像中非常小的噪音或者不相关的区域。
%8000排除了过大的MSER区域,以确保保留的区域适合于特定任务。
%ThresholdDelta控制MSER检测的敏感度,表示相邻像素之间的灰度值差异的阈值。在这里它被设置为4,意味着只有在相邻像素的灰度值差异>4时才会被认为是一个MSER区域
%mserConnComp包含了检测到的MSER区域的连通组件信息,可以用于后续处理,比如将检测到的区域连接成更大的区域或者执行其他操作。
figure;
imshow(I);%先显示原图
hold on;
plot(mserRegions, 'showPixelList', true, 'showEllipses', false);
title('MSER区域');
hold off;
%看图发现检测出1119个区域,就像python中的canny边缘检测一样。
效果如图所示:
2.根据基本几何属性去除非文本区域
此时我们可以用基于规则的方法删除非文本区域。比如,利用文本的几何属性,可以使用阈值过滤掉非文本区域。或者可以使用机器学习方法训练文本分类器和非文本分类器。下面实例使用一种根据几何属性的方法过滤非文本区域,使用regionprops函数测量其中的一些属性,然后根据属性值去除非文本区域。
1 | %测量MSER属性,用regionproperties也就是regionprops |
效果如图所示:

3.根据笔画宽度变化去除非文本区域
首先,笔画宽度是对组成字符的曲线和线条的宽度的度量。我们用笔画宽度区分文本区域和非文本区域。在文本区域中,笔画宽度的变化不会很大,而非文本区域中笔画宽度变化较大。我们这里使用距离变换和二进制细化操作实现这一点。
1 | %%获取区域的二进制图像,并且填充它以免在笔画宽度计算期间产生边界效果。 |
其中有一个重要函数
bwdist:bwdist(BW) computes the Euclidean distance transform of the binary image BW. For each pixel in BW, the distance transform assigns a number that is the distance between that pixel and the nearest nonzero pixel of BW.
可以看出我们要得到一个新的图像,其中的每个像素都是之前图像中,该像素到最小非0像素的距离(也就是默认白色是1,代表背景,黑色是0,代表文字),也就是黑色0到白色1的距离,所以白色的部分没有改变,而是黑色的背景部分改变了。而我们实际上重要的文字部分是二值中1,也就是白色部分,我们要计算白色到黑色的距离,就要先对图像二值取反,用~,如代码中所示。
之后变变成了1的部分计算到0的部分的最小距离,如图所示,这就是distanceImage了。
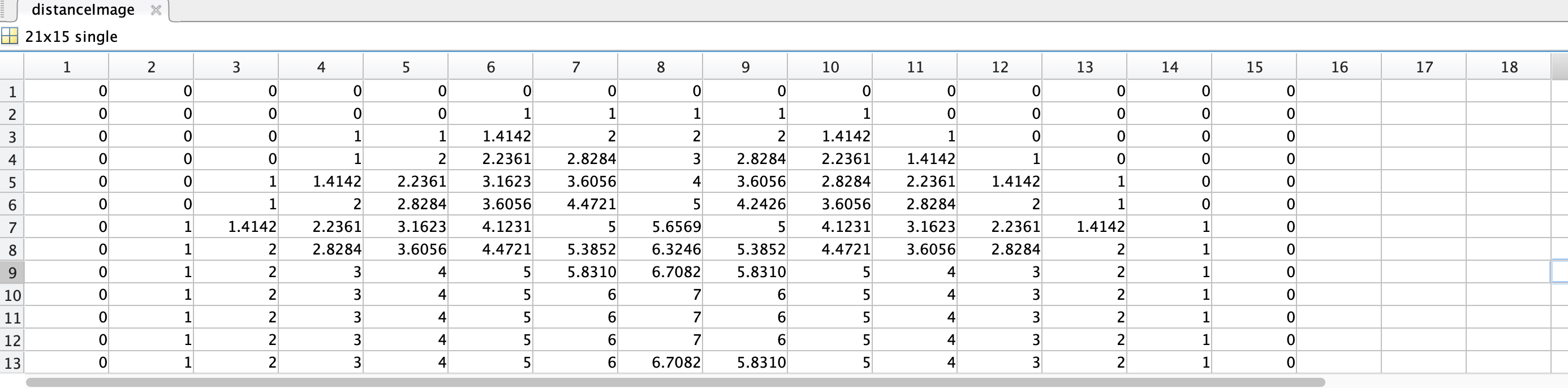
可以看出斜边最小时用勾股定理,其余就是线段最短。
然后就是对bwmorph函数的解释,
1 | %ocr function explanation |
四张图如图所示
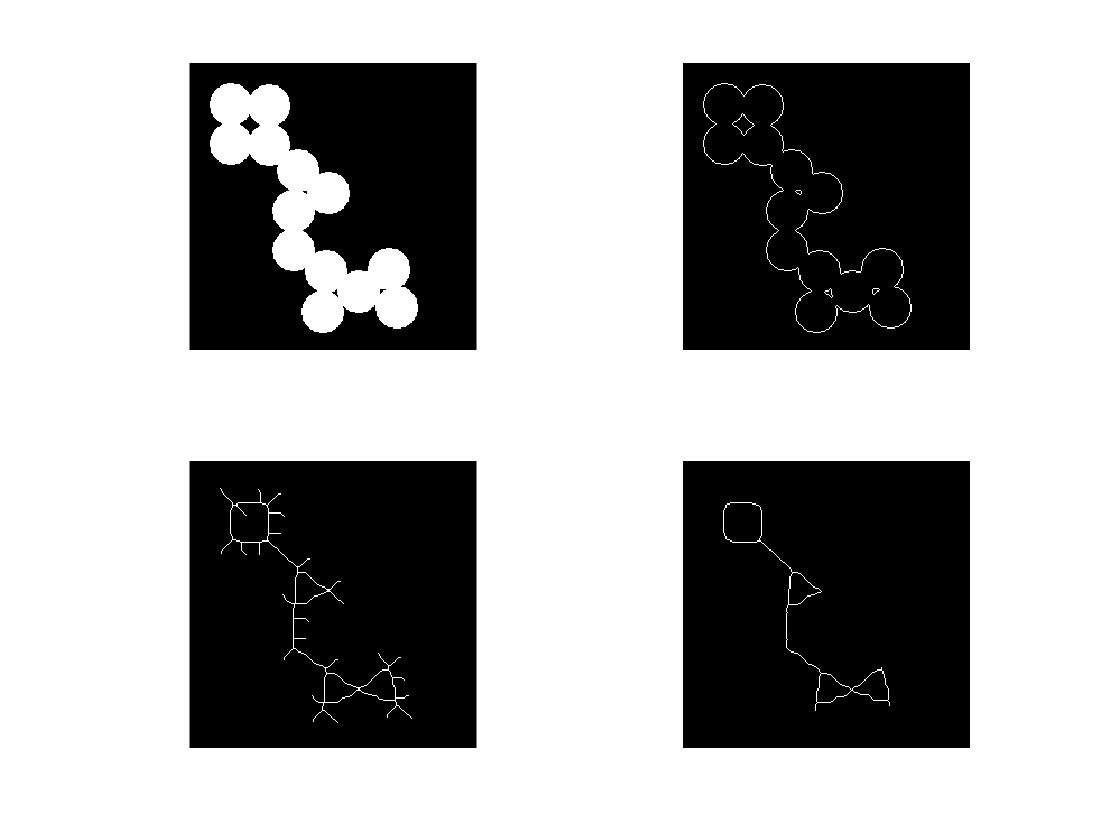
下图是strokeWidthImage经过skeletonImage过滤的图像。
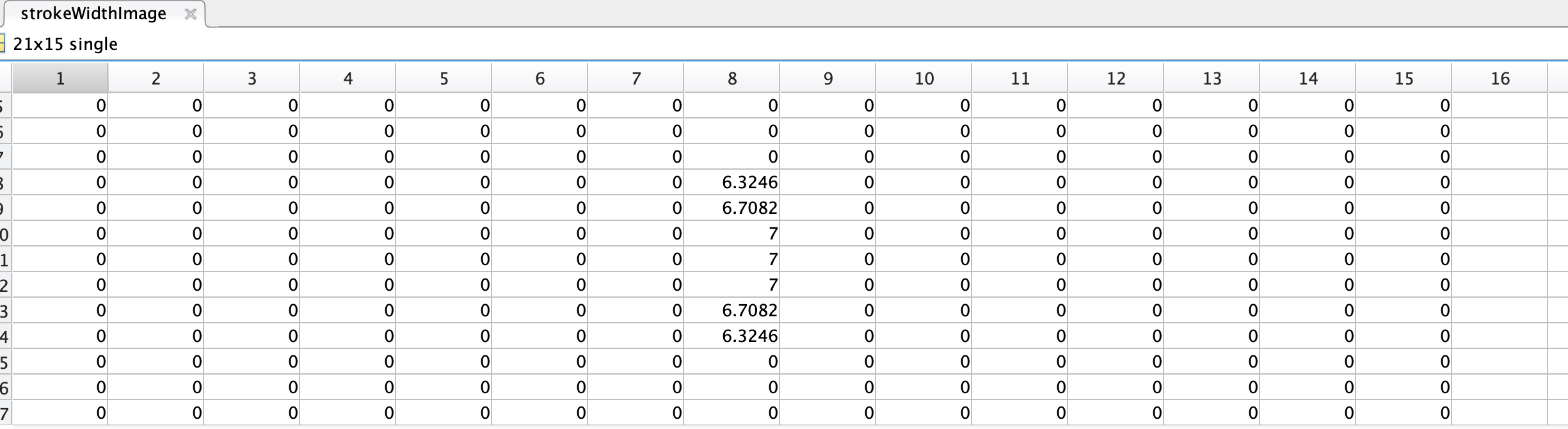
可以看到就剩下最后的笔画。
输出结果如图:
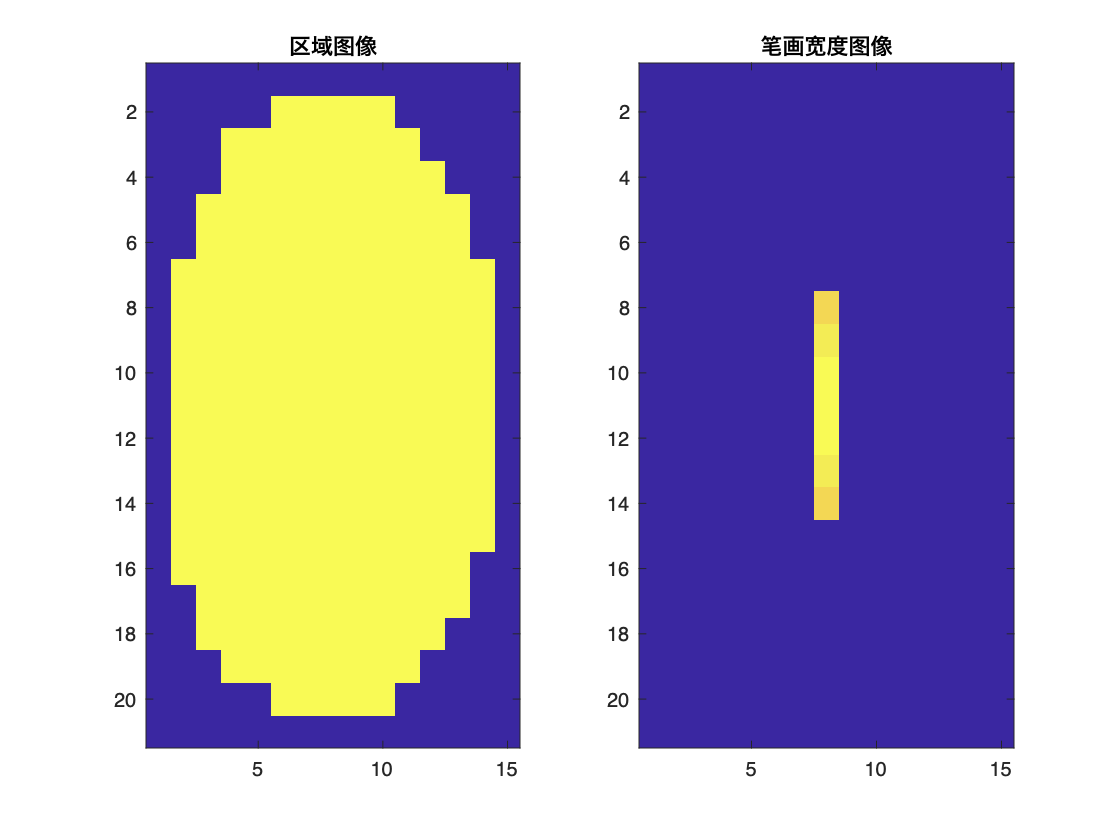
下面把strokeWidthImage中那一竖线,取出成矩阵。
1 | %图中发现笔画宽度图像在大部分区域几乎没有变化,表明该区域更可能是文本区域, |
如图:
然后可用阈值删除非文本区域。当然,阈值应该随着不同字样的图像调整优化。
1 | %%阈值笔画宽度变化度量 |
效果如图所示:
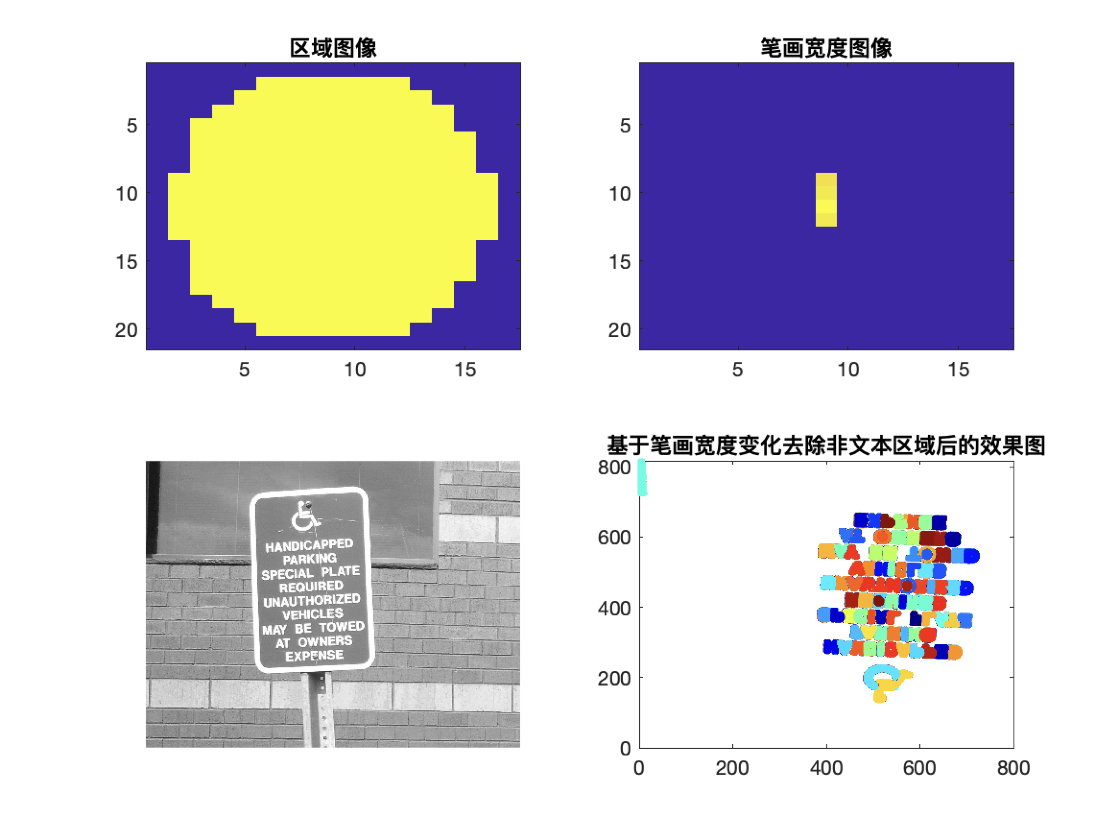
4.合并文本区域以获得最终检测结果
此时,我们已经得到的检测结果均由单个文本字符组成,要将这些结果用于识别任务(如ocr),单个文本字符就要合并为单词或者文本行,这让人们能够识别图像中具体的单词,因为单词比单个字符承载更多有意义的信息。
比如,识别一个字符串”TEXT”与单个字符{“T”, “E”, “X”, “T”},显然如果没有正确的顺序,那么单词的意思就会丢失。
将单个字符区域合并为单词或者一行文本的办法是先找到一个相邻的文本区域,然后在这些区域周围形成一个边框。为了找到相邻的文本区域,可以用区域道具扩展之前计算的边框。
这使得相邻文本区域的边框重叠,从而使属于同一单词或者文本行的文本区域形成重叠的边框链。
1 | %获取所有区域的边框 |
现在重叠的边框可以合并到一起,这样可以形成围绕单个单词或者文本行的单个边框。为此,我们要计算所有边框之间的重叠比率,这相当于计算所有文本区域之间的距离,从而可以通过寻找非零重叠比率来找到相邻文本区域的组。一旦得到成对重叠比率,就使用一个图来寻找所有由非零重叠比率”连接“的文本区域。(这句话很别扭)
我们下面合并这些检测单独文本的文本框
1 | %使用bboxOverlapRatio函数计算所有展开边框的成对重叠比率。 |
注意,这里我们解释一下componentIndices,这是一个行向量,例如,假设 componentIndices 如下所示:
1 | componentIndices = [0, 1, 1, 0, 1]; |
这表示有 5 个文本区域,分别属于三个组别。numRegionsInGroup 的计算如下:
1 | numRegionsInGroup = histcounts(componentIndices); |
在这个例子中,numRegionsInGroup 将是一个长度为 2 的向量,其中第一个元素表示组别 0 的文本区域数量,第二个元素表示组别 1 的文本区域数量。所以numRegionsInGroup维数就是组数2,两个分量分别是2和3也就是两个组分别包含的文本区域数量。
如果 numRegionsInGroup 的某个元素为 1,那么对应的组别中只包含一个文本区域。在 textBBoxes(numRegionsInGroup == 1, :) = []; 这行代码中,就会删除 textBBoxes 中那些属于只包含一个文本区域的组别的文本框。
最后提取文字即可。
1 | %使用ocr技术识别检测到的文本 |
但是MSER方法我们也可以看出,单单根据检测器候选文本区域是不行的,还需要根据场景,比如英文固定字体的字符检测,满足一些几何性质,我们就可以根据几何性质来去除非文本区域。所以加入了针对文本情景的特殊特征操作之后,才可以提高文本检测的精确度,所以操作复杂度较高,而单单的MSER检测器很难有高准确率。
 wechat
wechat