第七章 更灵活的定位内存地址的方法 简单的逻辑运算 1 2 3 4 and al,01111111B 代表将第七位设置为0 or al,10000000B 代表将第七位设置为1
ASCII码在汇编中的应用 比如我们要将一系列字母存储进数据段,我们可以直接输入字母,汇编会自动存储他们的ascii码比如:
1 2 3 4 5 6 7 8 9 10 11 12 assume cs:code,ds:data data segment db 'unIX' db 'foRK'#这里存入的是其ascii码也就是db 66h,6fh,52h,4bh相当于四个字节,也就说明一个字母代表一个字节 data ends code segment start: mov al,'a' mov bl,'b' mov ax,4c00h int 21h code ends end start
存入之后我们可以查看段数据-d可以看到右边就是ascii转换成的字符形式。
并且还能验证:因为ds = 0B2D,所以程序从0B3DH开始也就是直接对应第一个段data segment
大小写转换程序 平常我们知道小写字母的ascii码-20 = 大写字母的ascii码,但是我们在对小写字母减去20之后需要判断是否为大写字母,然而我们还没有学习判断语句,所以我们需要其他简洁的方法。
新方法:显然,大写字母ASCII码的第5位为0,小写字母的第5为为1。 我们只需要用逻辑运算变换第5位即可!程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 assume cs:codesg,ds:datasg datasg segment db 'BaSIC' db 'iNfOrMaTiOn' datasg ends codesg segment start: mov ax,datasg mov ds,ax#设置ds指向datasg段 mov bx,0#这样ds:bx就可以指向'BaSiC'的第一个字母 mov cx,5#设置循环次数 s: mov al,[bx]#取出 and al,11011111B#将al中的ascii码的第5位置为0,即转换为大写。 mov al,[bx]写回去 inc bx#bx自增 loop s mov bx,5#这样ds:bx就指向了第二个单词 mov cx,11 s0: mov al,[bx] or al,00100000B变为小写字母 mov [bx],al inc bx loop s0 mov ax,4c00h int 21h codesg ends end start
[bx+idata]定位内存 很简单,就是字面意思,偏移地址可以由bx中的数值加上idata
比如
也就是偏移地址为bx中的数值加上200,段地址在ds中,然后取出数据放入ax。
或者用以下格式
1 2 3 mov ax,[200+bx] mov ax,200[bx] mov ax,[bx].200
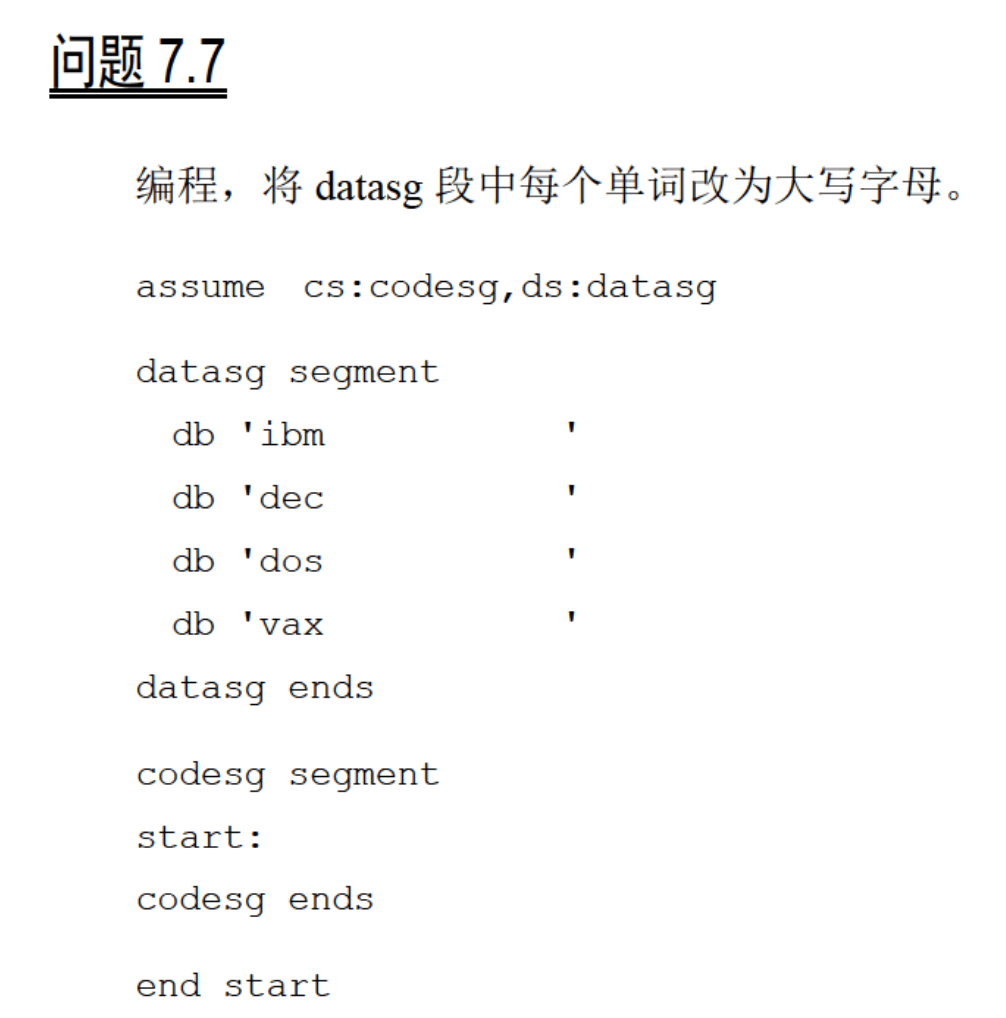
用[bx+idata]的方式进行数组的处理 例:在codesg中填写代码,将datasg中定义的第一个字符串转化为大写,第二个字符串转化为小写。 1 2 3 4 5 6 7 8 9 10 11 assume cs:codesg,ds:datasg datasg segment db 'BaSiC' db 'MinIX' datasg ends codesg segment start: codesg ends end start
所以我们可以用刚学的新的写偏移地址的方法定位第二个字符,
也就是
1 2 3 4 5 6 7 8 9 10 11 12 13 mov ax,datasg mov ds,ax mov bx,0 mov cs,5 s:mov al,[bx] and al,11011111b mov [bx],al mov al,[bx+5] mov al,00100000b inc bx loop s
非常简洁了。
如果换成c语言,也就是这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 char a[5 ]="BaSiC" ;char b[5 ]='MinIX' ;main() { int 1 ; i = 0 ; do { a[i]=a[i]&0xDF ; b[i]=b[i]|0x20 ; i++; } while (i<5 ); }
可以比较C语言和汇编定位两个字符串的方式
1 2 3 a[i],b[i] 0 [bx],5 [bx]其实很相似
SI和DI si和di是8086中和bx功能相似的寄存器,si和di不能够分成两个8位寄存器。下面的指令功能相同
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 1. mov bx,0 mov ax,[bx] 2. mov si,0 mov ax,[si] 3. mov di,0 mov ax,[di] 或者 1. mov bx,0 mov ax,[bx+123] 2. mov si,0 mov ax,[si+123] 3. mov di,0 mov ax,[di+123]
例:用si和di实现将字符串welcome to masm复制到其后面的数据区中 1 2 3 4 5 6 assume cs:codesg,ds:datasg datasg segment db 'welcome to masm!' db '................' datasg ends
首先我们分析,要复制的数据在datasg:0位置处要复制到16个字节以后也就是它后面的数据区偏移地址为16,代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 codesg segment start: mov ax,datasg mov ds,ax mov si,0 mov di,16 mov cx,8 s: mov ax,[si] mov [di],ax#也就是写入后面,注意ax为16位寄存器,所以一个写入两个字节。 add si,2 add di,2#两个偏移地址表示一次两个字节。 loop s mov ax,4c00h int 21h codesg ends end start
用更简洁的代码如何操作? 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 codesg segment start: mov ax,datasg mov ds,ax mov si,0 mov cx,8 s: mov ax,0[si] mov 16[si],ax add si,2 loop s mov ax,4c00h int 21h
[bx+si]和[bx+di]也可以指明内存单元 学到现在应该一目了然了吧,这是显而易见的。偏移地址也就是bx中的数值加上si中的数值。
下面来看一个题目
对于第一个mov ax,[bx+si]显然段地址2000,偏移地址应该为1000+0=1000,所以读取2000:1000执行后也就是ax=00BEh。后面的是不是道理相同?显然。
[bx+si+idata]和[bx+di+idata] 先补充几个常用写法:
1 2 3 4 mov ax,[bx].200[si] mov ax,[bx][si].200 mov ax,200[bx][si] mov ax,[bx+200+si]
来看一个相似的例题
这里显然段地址2000h,偏移地址应该为1000h+2+0=1002h所以读取之后ax=0006h。如果写的是+1那么应该读取0600h(复习一下偏移地址读取对应内存)
不同寻址方式的灵活应用 下面是几种定位内存地址的方式:
下面来看一个例题:
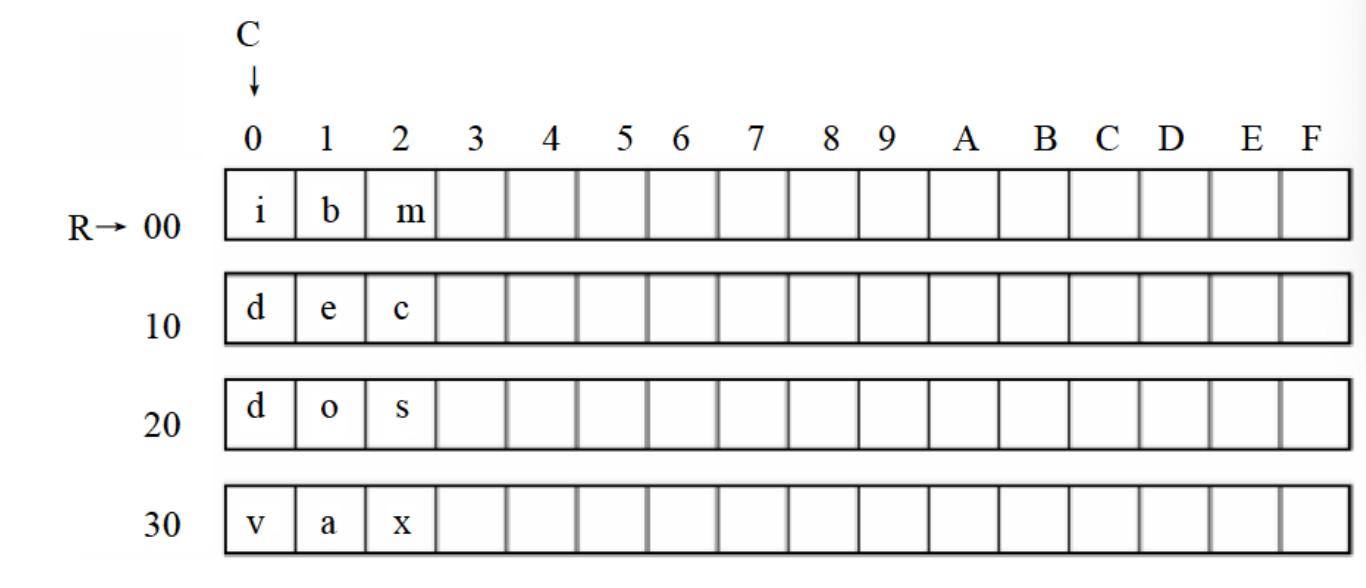
我们可以看一下数据的存储结构,如图所示:
所以我们需要二重循环,外层循环按照行进行,内层循环按照列进行,先修改完每一列,然后定位到下一行。
程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 mov ax,datasg mov ds,ax mov bx,0 mov cx,4 s0:mov si,0 mov cx,3 s:mov al,[bx+si] and al,11011111B mov [bx+si],al inc si loop s add bx,16 loop s0
其实存在问题,因为cx只有一个但是却两次赋值用于两个循环,肯定不妥。
所以我们可以将外层循环的cx中的数值保存起来,在执行外层循环的loop指令前,再恢复外层循环的cx数值。可以用dx寄存器来临时保存cx中的数值。程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 mov ax,datasg mov ds,ax mov bx,0 mov cx,4 s0: mov dx,cx#保存数值 mov si,0 mov cx,3#将cx设置为内层循环的次数 s: mov al,[bx+si] mov al,11011111B mov [bx+si],al inv si#推向下一列 loop s add bx,16#推向下一行 mov cx,dx#还原外层循环次数 loop s0#使得cx中值-1
如果寄存器不够用,我们可以开辟一段内存空间。改进程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 assume cs:codesg,ds:datasg datasg segment db 'ibm ' db 'dec ' db 'dos ' db 'vax ' dw 0 #定义一个字用来暂存cx datasg segment start: mov ax,datasg mov ds,ax mov bx,0 mov cx,4 s0:mov ds:[40H],cx#将外层循环的cx值保存在datasg:40单元中 mov si,0 mov cx,3#内层循环三次 s: mov al,[bx+si] mov al,11011111B mov [bx+si],al inc si loop s add bx,16#下一行 mov cx,ds:[40H]#恢复外层cx的值 loop s0 mov ax,4c00h inc 21H codesg ends end start
但是我们有时需要记住存放在哪个单元中了,所以不是很方便存储大量cx,最好的方法是使用栈。新的程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 assume cs:codesg,ds:datasg,ss:stacksg datasg segment db 'ibm ' db 'dec ' db 'dos ' db 'vax ' datasg ends stacksg segment#定义一个栈段容量为16个字节 dw 0,0,0,0,0,0,0,0 stacksg ends codesg segment start:mov ax,stacksg mov ss,ax mov sp,16 mov ax,datasg mov ds,ax mov bx,0#列起始 mov cx,4 s0:push cx#将外层循环值压栈 mov si,0 mov cx,3#内层循环值 s:mov al,[bx+si] and al,11011111B mov [bx+si],al inc si loop s add bx,16 pop cx#将外层循环值出栈开始外层循环。 loop s0 mov ax,4c00h inc 21H





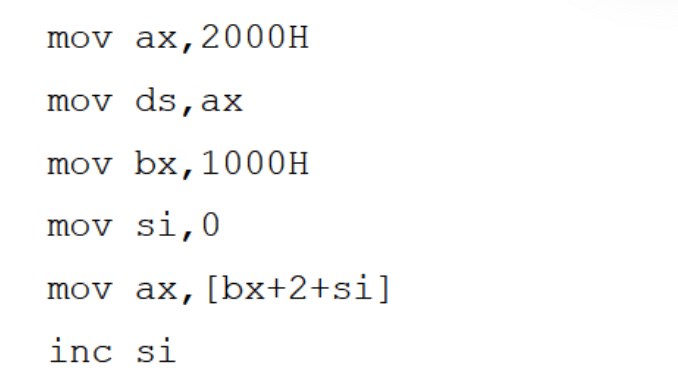

 wechat
wechat